英文翻译
- NAT traversal : NAT 穿越
- NAT Hole Punching : NAT 打孔
定义
(UDP) 打洞技术是通过中间公网服务器的协助在通信双方的 NAT 网关上建立相关的映射表项,使得双方发送的报文能直接穿透对方的 NAT 网关(防火墙),实现 P2P 直连。
洞:所谓的洞就是映射规则,外部能够主动与之通信的规则
为何要打洞?(why)
直接连不行吗?
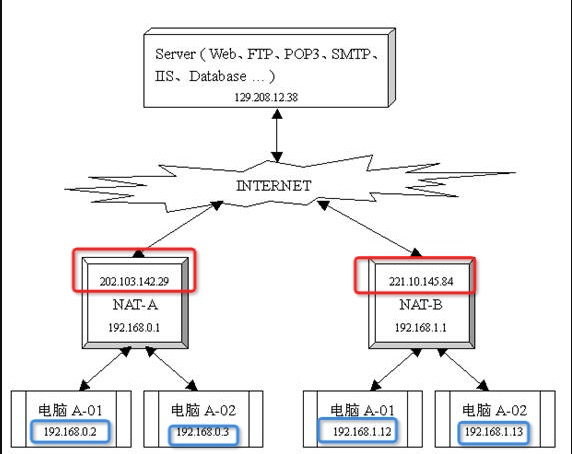
- NAT 技术的存在,一方面减缓了 IPV4 的需求,使得私网 IP 地址通过映射成公网 IP 地址的方式与外界通信
- 但另外一方面, NAT 也对安全性做了限制(防火墙),外界不能主动与私网 IP 进行通信
打洞有什么好处?
- 节省流量
- 降低中心服务器压力
- 下载速度快(比如迅雷、直播等)
- 安全性和私密性
如何打洞?(how)
通常我们说的打洞技术基本上都是使用 UDP 来实现的,当然 TCP 也行,只不过会复杂一点(后面我们讨论一下 TCP 打洞)。
使用中继设备(proxy)
主要利⽤第三⽅的服务器作为中转服务器,⽐如Application Level Gateway (ALG),application server, application server with agent, TURN。
有点是稳定可靠,缺点是延迟较⼤,不适合在p2p的⽹络中使⽤。
本质上其实不算 P2P 打洞的范畴了。
直连
基本思路是:A 和 B 互相知道对方的公网 IP:Port,使用对方公网 IP:Port 通信。
通过修改通信协议,或者 NAT 设备来帮助节点之前的直接通信,⽐如: tunnel, NAT-PMP, UPnP, MidCom, STUN hole punching, ICE, Teredo等。 其中STUN hole punching⽅法在实践中应⽤最为 广泛。
- UPnP: 把内网 IP 直接映射为 NAT 外网 IP (纯转发模式),类似公网 IP
- STUN: 比较出名的打洞协议,本质上就是利用一台或多台公网服务器协助位于不同私网的两个节点 A 和 B 进行打洞。
NAT 设备类型
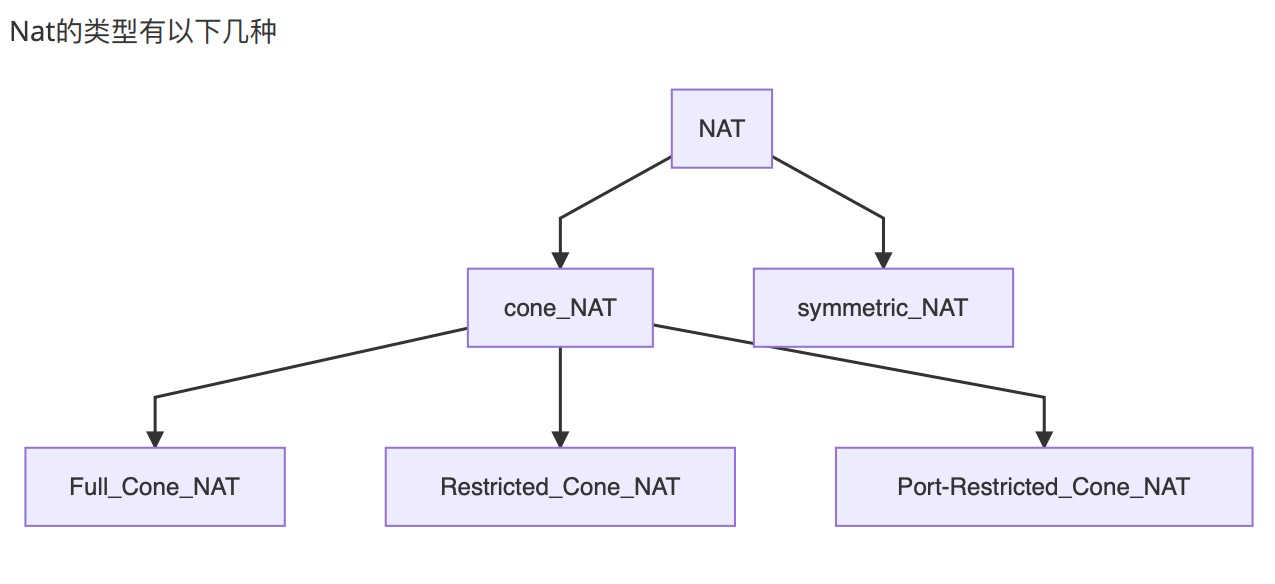
Full Cone NAT: 允许任何外部 IP 任何端⼝连⼊ NAT,只要 NAT 内部 host 产⽣过 IP 端⼝映射。 (不限制任何 IP)
Restricted Cone NAT: 只允许外部指定 IP 连⼊当前 NAT,即 NAT 内 host 主动连 接过的 IP。(限制 IP)
Port-Restricted Cone NAT:只允许内⽹设备主动 连接过的外⽹ IP 和 Port 连⼊。(限制 IP + Port)
Symmetric NAT:这种类型的 NAT ⾏为跟端⼝限制型的 NAT 类型相似,不同的是,对于向外连接的不同的 IP 和 Port,NAT 随机分配⼀个 Port 来完成地址转换,完成对外连接。(只要向外的 IP:Port 不一致则映射到不同端口)
注意:对于前三种 NAT 设备,内网节点连接不同的 server {IP, Port} 对映射外网端口一致;
主要有以上几种,市面上还有少量的其他类型
Full Cone NAT (全锥形)
- NAT 映射规则形成后,外部其他主机能够主动与之通信
举例如下:
- A 位于私网内部
- A 访问 https://www.google.com/
- NAT-A 记录了映射规则,比如 {local_host,local_port,public_port,dest_host} 等信息
- 外部其他主机(比如 google.com) 能主动与 A 通信(通过 A 的 public_ip:public_port)
Restricted Cone NAT(限制型)
在 Full Cone NAT 的基础上多加了一条限制规则:
- 只允许访问过的 server IP 与之通信
举例如下:还是上面的例子,后续只允许 https://www.google.com/ (对应 IP 203.107.53.50) 与之通信,而不 care 203.107.53.50 的端口号(比如从 6666 端口过来的数据)。
Port-Restricted Cone NAT(端口限制型)
在 Restricted Cone NAT 的基础上多加了一条限制规则:
- 只允许访问过的 server {IP, Port} 与之通信
举例如下:还是上面的例子,后续只允许 https://www.google.com/ (对应 IP 203.107.53.50) 的 80 端口与之通信,其他端口不行。
Symmetric NAT(对称型)
访问规则同 Port-Restricted Cone NAT:
- 只允许访问过的 server {IP, Port} 与之通信
区别是连接不同的 server {IP, Port},映射到 NAT 上的公网 Port 不一致,且映射规则不确定。
有些 NAT 设备会进行简单的 +1 操作实现端口映射,比如:{local_port: 6000, public_port: 6000, Server1},{local_port: 6000, public_port: 6001, Server2},{local_port: 6000, public_port: 6003, Server3}
有些 NAT 设备为了安全性,可能会随机进行端口映射,提高端口猜测的难度。
场景分析
(假设已经获取到⽬标邻居的IP Port 等信息)
- 先向公⽹服务器发起请求,探测⾃⼰是不是在⼀个 NAT 下
- 如果不在,说明自己是公网节点,可以与目标建立连接(让目标主动连接)
- 如果在,则获取⾃⼰的 NAT 类型是什么,根据不同的类型采取相应不同的策略
注意:A 和 B 均要与 server 一致保持连接心跳,确保 NAT 映射端口有效
节点 A 在 NAT 下面,节点 B 在公网环境中
打洞策略:
- 只要保证节点 A 主动向节点 B 发起连接,两者就可以连接成功
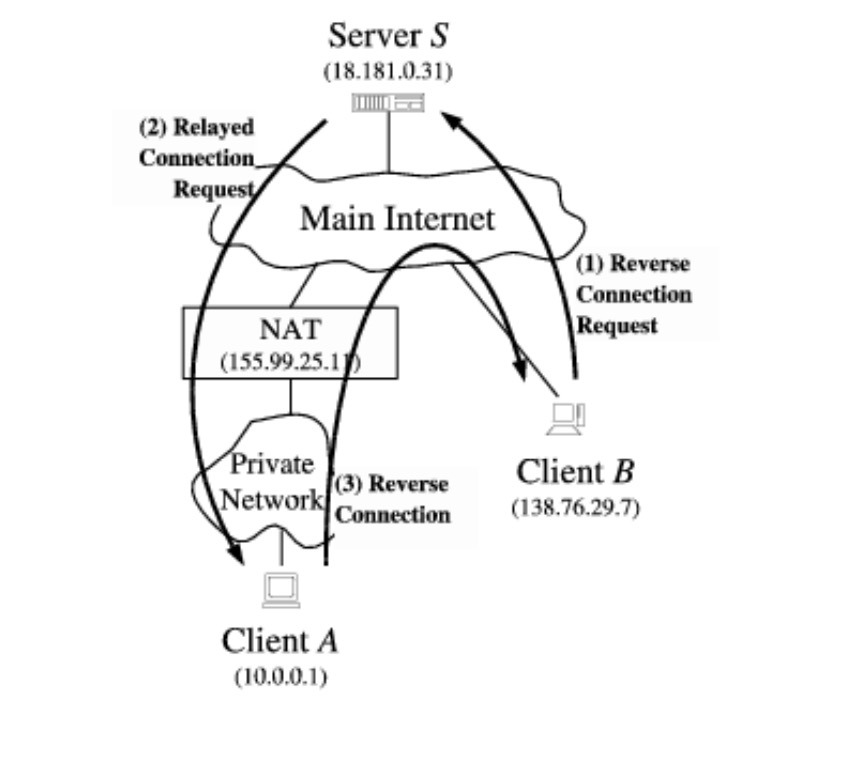
节点 A 和 B 在相同的 NAT 下
打洞策略:
- A 从 server 获取 B 的信息,server 同时发给 A 和 B 对方的信息(公网/私网信息)
- A 与 B 各自收到 server 的信息后,同时向对方发起连接,公网和私网都发(理论上私网会快一点),一旦收到回复,则停止
- 建立连接成功
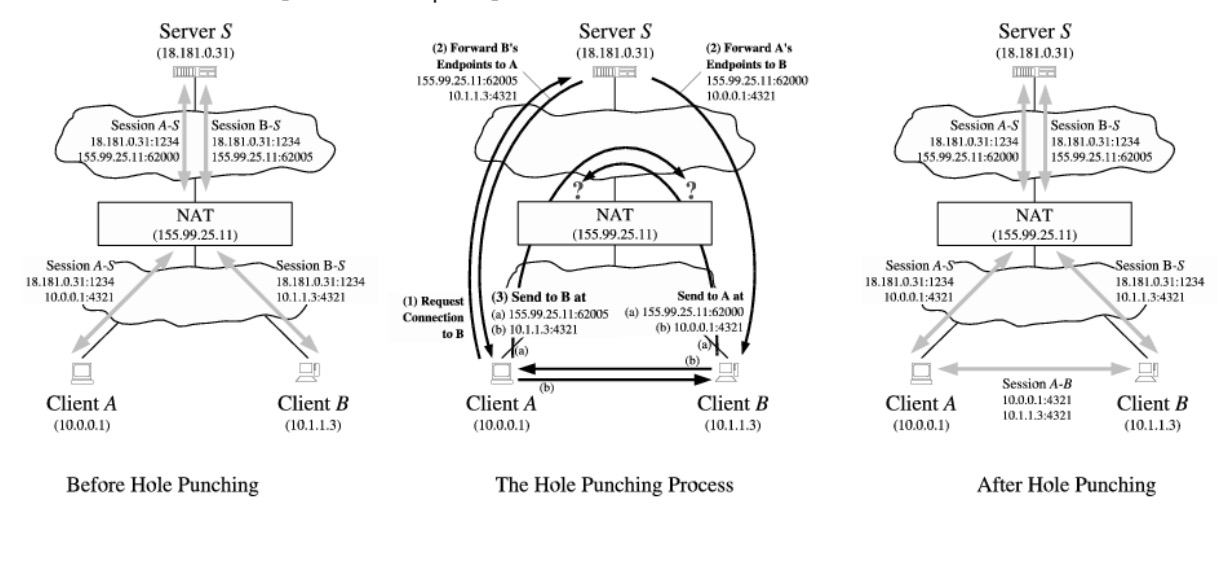
节点 A 和 B 在不同的 NAT 下(这是我们要重点讨论的)
节点 A 和 B 的 NAT 可能是任意一种 NAT 类型
- A 和 B 均是锥形 NAT
- A 和 B 分别是对称型和普通锥形(全锥形,限制型锥形)
- A 和 B 分别是对称型和 Port-Restricted Cone NAT (端口限制型)
- A 和 B 都是对称型
A 和 B 均是锥形 NAT
锥形 NAT 之间可以容易的打洞成功,具体流程如下:
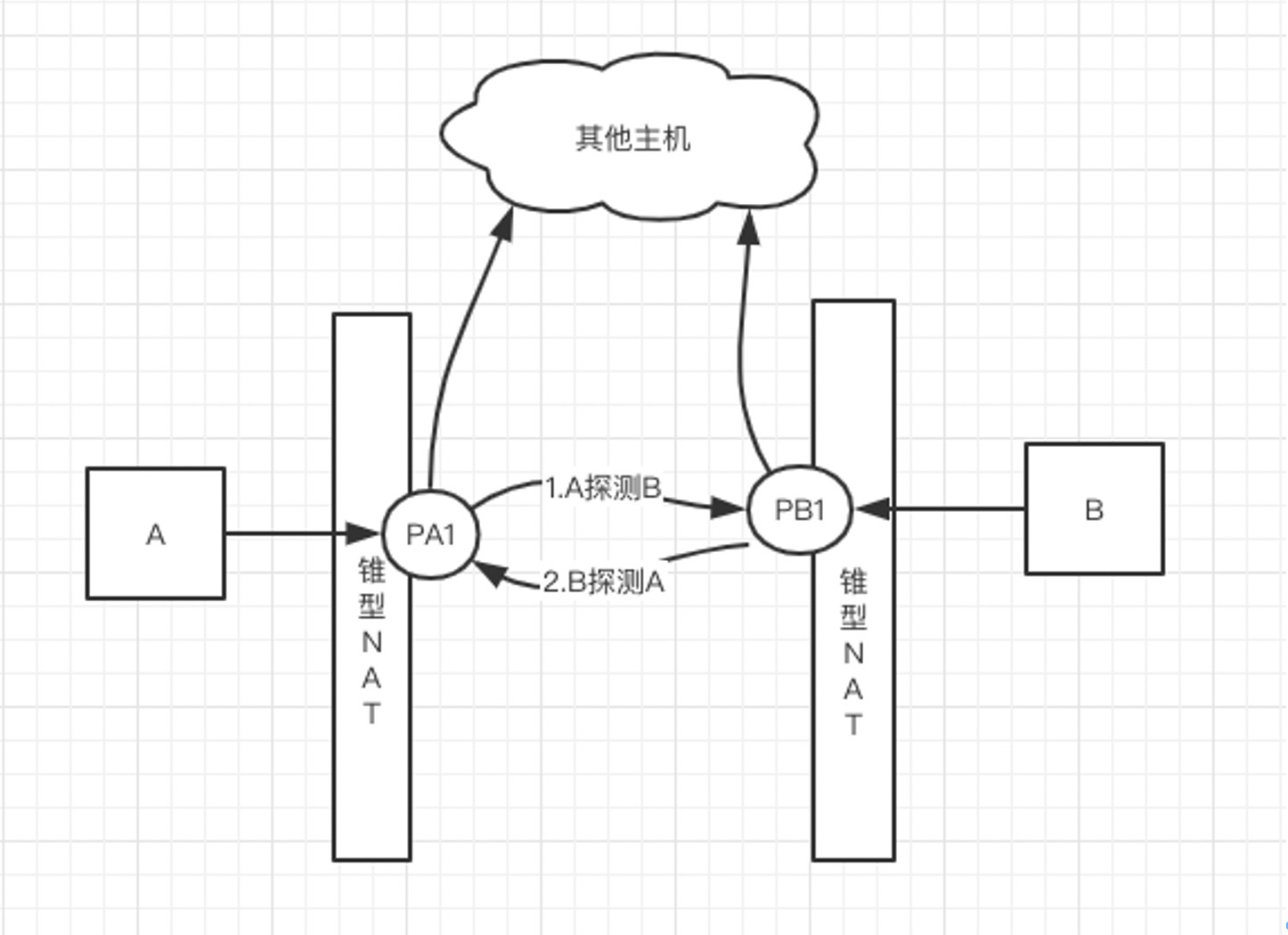
以下流程假定已经完成了 NAT 类型探测,A/B 知道自己的 NAT 类型,以及通过 NAT 映射出去的端口 PA1/PB1。
打洞策略:
- A 向 server 发起与 B 的打洞请求,server 向 B 转发打洞请求,同时A 向 PB1 直接发送探测包,那么 A 为 B 在 PA1 已经成功打洞,但是 A 的消息无法到达,因为 B 的 NAT 会将不明的地址(PA1) 丢弃。(注意:这里有可能不是丢弃,而是拒绝)
- B 收到从 server 转发过来的打洞请求后,向 PA1 直接发送探测包,这时 B 的 NAT 可以放行 PA1 的消息了,也就是 B 为 A 在 PB1 上完成了打洞。
- 至此,A 和 B 消息能够互通,打洞成功
注意,上面斜体部分,NAT 对不明地址的行为可能是拒绝,待会会讨论。
A 和 B 分别是对称型和普通锥形(全锥形,限制型锥形)
假设 A 是对称 NAT,B 是普通锥形:
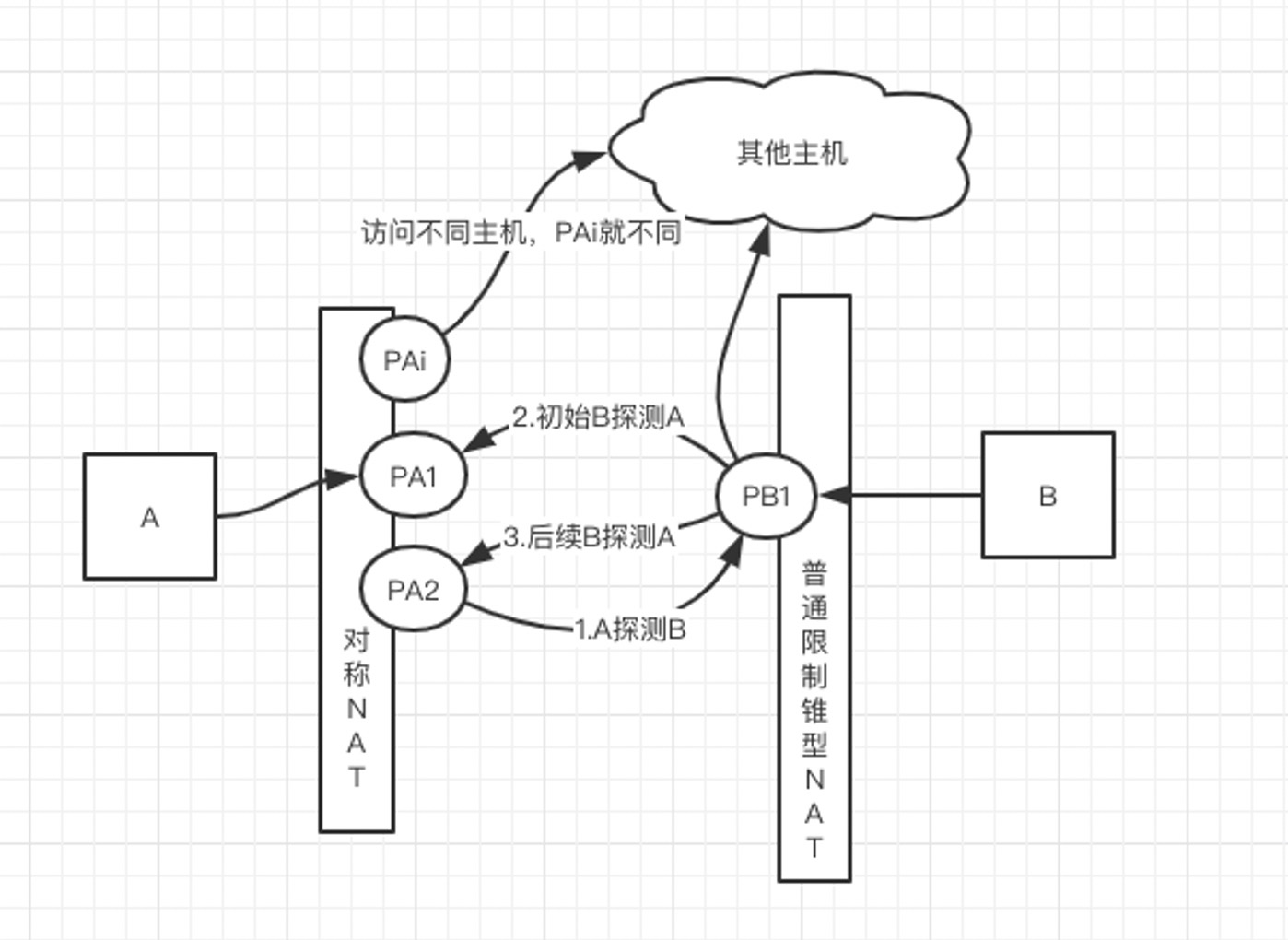
打洞策略:
- A 向 server 发起与 B 的打洞请求,server 向 B 转发打洞请求,同时发送探测包到 PB1,这个探测包是从 PA2 发出的,不是 PA1(因为对称型)。也就是 A 在端口 PA2 为 PB1 完成打洞,同时 B 的 NAT 会丢弃来自不明地址 PA2 的包。(注意:这里有可能不是丢弃,而是拒绝)
- B 收到从 server 转发过来的打洞请求,向 PA1 发送初始探测包(一开始不知道 PA2),这个时候 B 已经为 A 在 PB1 打好洞,至此 PA2 的消息能够通过 PB1 到达 B。(注意:因为是普通锥形,不对端口做限制,所以从不同端口 PA2 过来的包能被 B 接受)
- 经过步骤2,B 可以收到 PA2 的消息,同时结合 A 的 NAT 类型,重新改发探测包到 PA2,于是 A 在 PA2 能收到 PB1 的探测包,至此 A 和 B 消息可以互通,打洞成功
如果 A 和 B 正好角色相反,那么可以调整打洞的方向即可
A 和 B 分别是对称型和 Port-Restricted Cone NAT (端口限制型)
原本大致过程是同上面一种场景,但是由于 B 是端口限制型 NAT,会导致 PB1 只允许 PA1 通过(上面红色字体部分B 已经为 A 在 PB1 打好洞),从而 PA2 过来的包会被 B 的 NAT 拒绝,导致打洞失败。
A 和 B 都是对称型
由于 A 和 B 均是对称型 NAT,那么比上面一种场景更严格,A 和 B 探测得到的公网 Port 均会被修改,无法完成打洞。
对称型打洞真的没有办法了吗?
我们再来考虑对称型和端口限制型的打洞,由于 B 收到 server 转发过来的打洞请求后,是向 PA1 发送探测包的,因为 B 只知道 PA1(PA1 是 A 与 server 连接是映射的端口号,server 也只知道 PA1),但是 A 由于是对称型 NAT,会从一个新端口 PA2 向 B 发包,但是 B 由于是端口限制型,只允许 PA1 端口的包通过,所以 B 会拒绝 PA2。
还是上面那张图:
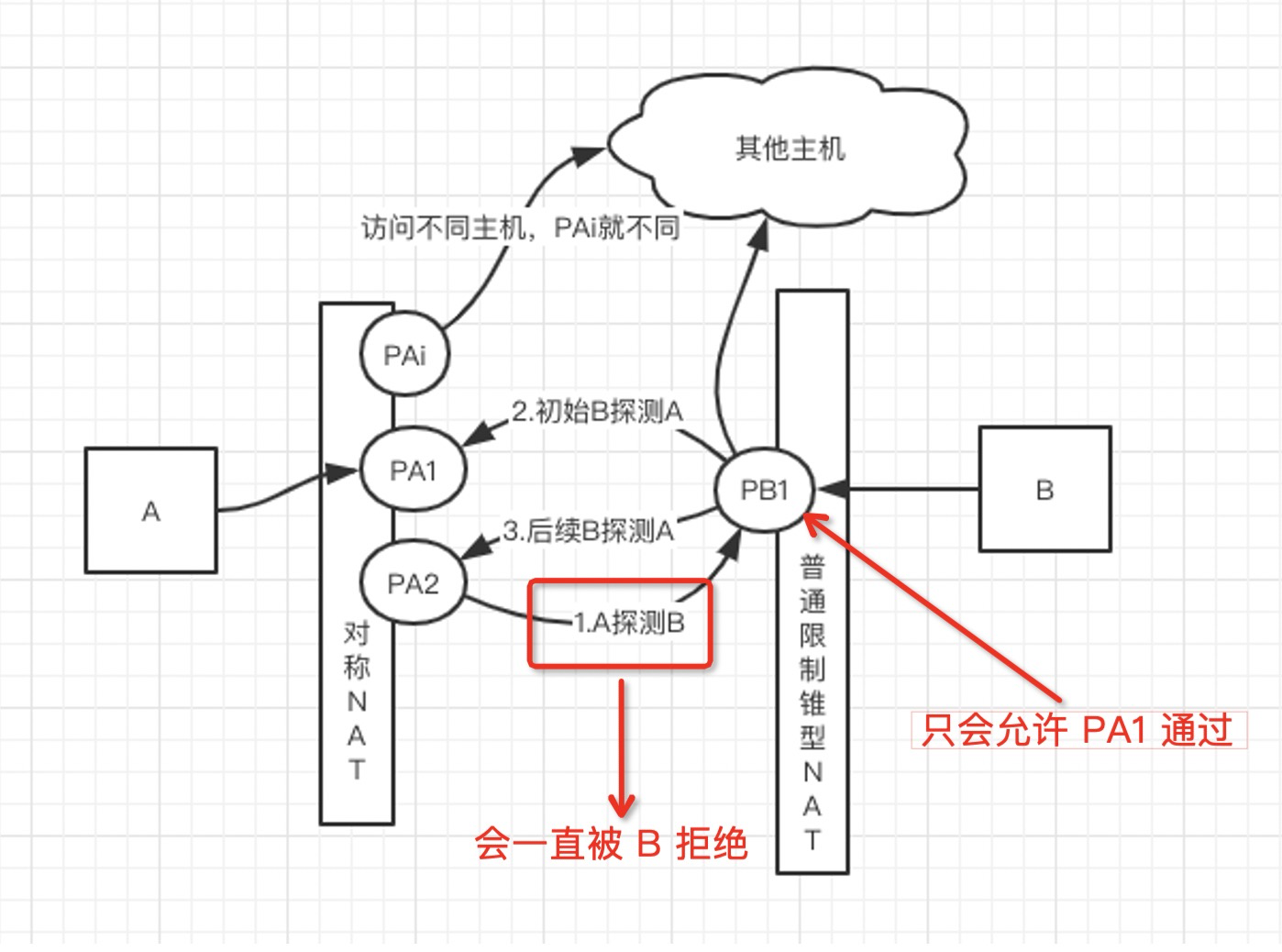
A 从 PA2 发向 B 的包一直会被 B 拒绝,也就是说 B 无法在 NAT-B 上为 A 打洞。
那假如 B 探测包不是发往 PA1 而是 PA2 呢?那 A 和 B 就能打洞成功。
那么问题来了,B 如何知道 PA2 呢?
通常来讲,有两种办法:
- 端口探测
- 端口预测
端口探测
对于对称型的 NAT在映射内网端口的时候,有一些 NAT 设备会采取比较傻瓜的端口分配方法,比如进行简单的线性变化。
- 比如每次分配的端口号递增 1
- PA2 = (PA1 + PB1 + IPA + IPB) % 65535
对于这种 NAT,要探测这种特性需要用到两台及以上的公网 server,通过与不同的 server 连接映射的公网 Port,归纳总结自己的 NAT 映射规律,那么对于 B 来说,打洞的时候第一次向 A 发包,就直接往 PA2 发包就好了。
端口预测
有一些对称型 NAT 为了安全考虑,分配端口的方法难以预测,比如随机分配端口,那么对于这种情况,如何预测端口号呢?
- 基于一个理论:生日攻击理论
生日攻击理论讲的是在一个班级里,每个人的生日可能是 365 天里的任何一天,每年有 365 天,如果要让 至少有两人的生日相同的概率超过 50%,问这个班级最少需要多少人?
答案是:(xx)
是不是出乎预料?
生日攻击理论说的直白点就是,利用了远小于样本集的尝试次数,就能够很大概率获得两个相同的碰撞采样结果。
那么针对端口号的样本集 65535,实际是 (1025, 65535],双方随机打洞需要尝试多少次(打多少洞)才能刚好碰撞成功呢?
1 | cat nat_birth_attack.py |
运行结果:
1 | >>> python nat_birth_attack.py ‹git:master ✘› 11:00.53 四 3 25 2021 >>> |
把 total 修改成 65535,概率 rate 修改成 80%,计算得到尝试次数为 460 次。
1 | total:65536 trytimes:460 result:0.801039 > target_rate:0.8 success |
也就是说对于 B 来说,可以尝试随机往 A 的 460 个不同的端口发探测包,就有 80% 的概率能够正好预测到 NAT-A 随机分配的 PA2。
460 个探测包的代价基本可以忽略不计。
至此,可以完美实现对称型和端口限制型的打洞。然而遗憾的是,对于对称型和对称型打洞,依然无法实现。
再来讨论下 NAT 对陌生地址包的行为
上面能够打洞成功的场景下,都是基于一个前提是 NAT 对陌生地址发来的包采用的是丢弃策略。这里的陌生地址指的是自己没有主动往外发包的 {dest_ip, dest_port} 对。
如果不是丢弃,而是采用黑名单机制呢?为了安全考虑,有一些 NAT 在收到陌生地址的包后,会触发防火墙模块,并且在自己的 deny 列表中增加一项{PA2, PB1},随后自己再往 A 发包的时候,本来打算使用 PB1 进行发包,但是发现 deny 列表里已经存在了 PB1,于是会重新选择一个端口号 PB2 发包。于是对于这种锥形 NAT 会退化成对称型的 NAT。
知道了这个原理,要解决也很容易。
- 设置有限 TTL,避免惊动对方防火墙
一开始 A 往 B 发包,可以设置 TTL 为 3,这个数大到足够通过自己的外网 NAT(可能有多层),又会被中间的某个运营商 router 丢弃,从而不会惊动 B 的防火墙模块,同时为 B 打好了洞。
同理,B 也做类似的操作,为 A 打好洞
A 和 B 两边都等待一段时间,比如 2 s
再互相发探测包,不用设置 TTL
打洞成功
关于 TTL 的值设置为多少,需要做一定的探测,不然可能设置过小,也许都没有走出自己的 NAT,设置过大,可能导致惊动了对方的防火墙
总结一下
| NAT | 全锥形 | 限制型锥形 | 端口限制型锥形 | 对称型 |
|---|---|---|---|---|
| 全锥形 | Direct | Direct | Direct | Direct |
| 限制型锥形 | Direct | Hole Punch | Hole Punch | Hole Punch |
| 端口限制型锥形 | Direct | Hole Punch | Hole Punch | Hole Punch |
| 对称型 | Direct | Hole Punch | Hole Punch | Relay |
扩展:讨论一下 TCP 打洞的可行性
TCP 也能实现 NAT 打洞,只不过相比 UDP 会更复杂一点。原因是:
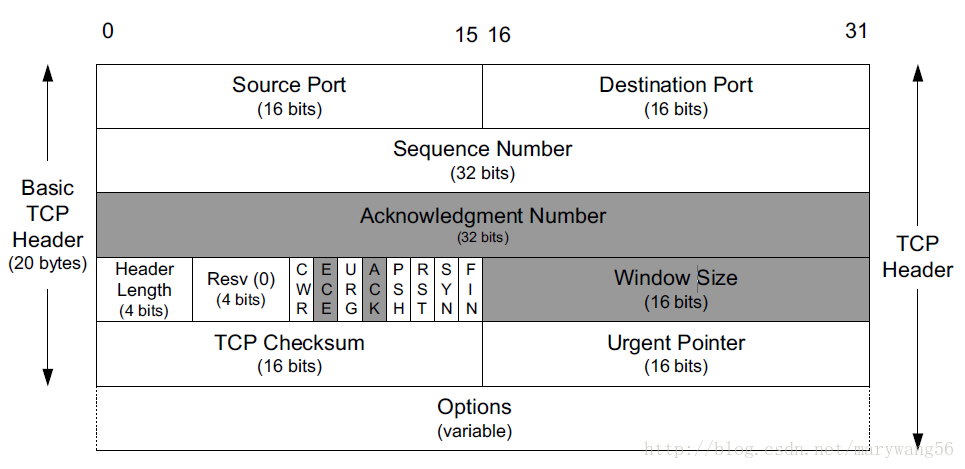
- 一个UDP套接字由一个二元组来标识,该二元组包含一个目的地址和一个目的端口号;而一个TCP套接字是由一个四元组来标识,包括源IP地址、源端口号、目的IP地址、目的端口号
- TCP 套接字仅允许建立 1 对 1 的响应,即应用程序将一个套接字绑定到本地的端口后,试图将第二个套接字绑定到该端口的操作都会失败
基本打洞策略如下:
- A 和 B 分别位于不同的 NAT 下面
- A 启动 tcp client,bind 一个 local_port PA1’,执行 connect 连接公网 tcp server,server 获取 A 的映射公网端口 PA
- B 同上,B 启动 tcp client,bind 一个 local_port PB1’,执行 connect 连接公网 tcp server,server 获取 B 的映射公网端口 PB
- A 和 B 保持和 server 的连接,不断开,避免各自的 NAT 上的映射规则过期 {PA1’ -> PA} 和 {PB1’ -> PB1}
- A 和 B 通过 server 互相获取对方的公网 Port PA1 和 PB1,准备开始打洞
- A 新启动一个 tcp 套接字,使用 SO_REUSEADDR/SO_REUSEPORT 绑定到之前与 server 连接的本地端口,也就是 PA1’,并且调用 listen 处于等待监听状态
- B 同上,bind PB1’ 并且调用 listen 处于监听状态
- A 再新建一个套接字 bind 到之前的端口,调用 connect 发起向 PB1 的连接,也就是 A 往 PB1 发送 syn 包,也就是为 B 打洞,NAT-B 会丢弃这个包
- 同时 B也再新建一个套接字 bind 到之前的端口, 也调用 connect 发起向 PA1 的连接,也就是 B 往 PA1 发送 syn 包,也就是为 A 打洞
- 假设 A 发送完 syn 之后,B 的 syn 包达到了 NAT-A,NAT-A 能通过,这个时候有的 linux 系统上 A 会认为自己的异步 connect 调用成功,同时利用相同的 seq 发送 SYN+ACK 包 到 PB1,NAT-B 也能顺利通过,再返回 ACK 包,连接建立成功;有的 linux 系统会走正常的 accept 操作,也能顺利建立连接
扩展:讨论一下打洞的有效时间
在 NAT 上的映射规则有失效时间,如果要保持洞口的有效性,需要保持打洞双方的心跳。比如在手机上,这个洞口可能会在 1 min 后失效
扩展:讨论一下多层 NAT 的打洞
我感觉其实单层 NAT 应该是类似的。
Blog:
2021-03-28 于杭州
By 史矛革