1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
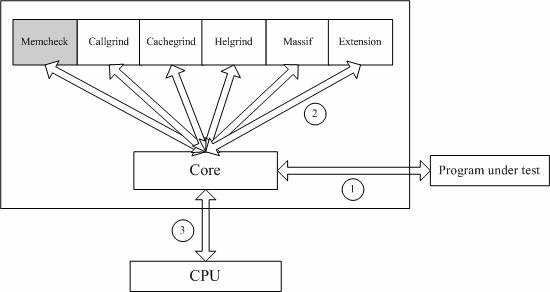
MASSIF OPTIONS
Specifies whether heap profiling should be done.
If heap profiling is enabled, gives the number of administrative bytes per block to use. This should be an estimate of the average, since it may vary. For example, the
allocator used by glibc on Linux requires somewhere between 4 to 15 bytes per block, depending on various factors. That allocator also requires admin space for freed blocks,
but Massif cannot account for this.
Specifies whether stack profiling should be done. This option slows Massif down greatly, and so is off by default. Note that Massif assumes that the main stack has size zero
at start-up. This is not true, but doing otherwise accurately is difficult. Furthermore, starting at zero better indicates the size of the part of the main stack that a user
program actually has control over.
Tells Massif to profile memory at the page level rather than at the malloc'd block level. See above for details.
Maximum depth of the allocation trees recorded for detailed snapshots. Increasing it will make Massif run somewhat more slowly, use more memory, and produce bigger output
files.
Functions specified with this option will be treated as though they were a heap allocation function such as malloc. This is useful for functions that are wrappers to malloc or
new, which can fill up the allocation trees with uninteresting information. This option can be specified multiple times on the command line, to name multiple functions.
Note that the named function will only be treated this way if it is the top entry in a stack trace, or just below another function treated this way. For example, if you have a
function malloc1 that wraps malloc, and malloc2 that wraps malloc1, just specifying
This is a little inconvenient, but the reason is that checking for allocation functions is slow, and it saves a lot of time if Massif can stop looking through the stack trace
entries as soon as it finds one that doesn't match rather than having to continue through all the entries.
Note that C++ names are demangled. Note also that overloaded C++ names must be written in full. Single quotes may be necessary to prevent the shell from breaking them up. For
example:
Any direct heap allocation (i.e. a call to malloc, new, etc, or a call to a function named by an
ignored. This is mostly useful for testing purposes. This option can be specified multiple times on the command line, to name multiple functions.
Any realloc of an ignored block will also be ignored, even if the realloc call does not occur in an ignored function. This avoids the possibility of negative heap sizes if
ignored blocks are shrunk with realloc.
The rules for writing C++ function names are the same as for
The significance threshold for heap allocations, as a percentage of total memory size. Allocation tree entries that account for less than this will be aggregated. Note that
this should be specified in tandem with ms_print's option of the same name.
Massif does not necessarily record the actual global memory allocation peak; by default it records a peak only when the global memory allocation size exceeds the previous peak
by at least 1.0%. This is because there can be many local allocation peaks along the way, and doing a detailed snapshot for every one would be expensive and wasteful, as all
but one of them will be later discarded. This inaccuracy can be changed (even to 0.0%) via this option, but Massif will run drastically slower as the number approaches zero.
The time unit used for the profiling. There are three possibilities: instructions executed (i), which is good for most cases; real (wallclock) time (ms, i.e. milliseconds),
which is sometimes useful; and bytes allocated/deallocated on the heap and/or stack (B), which is useful for very short-run programs, and for testing purposes, because it is
the most reproducible across different machines.
Frequency of detailed snapshots. With
The maximum number of snapshots recorded. If set to N, for all programs except very short-running ones, the final number of snapshots will be between N/2 and N.
Write the profile data to file rather than to the default output file, massif.out.<pid>. The %p and %q format specifiers can be used to embed the process ID and/or the
contents of an environment variable in the name, as is the case for the core option
|