Valgrind Massif
valgrind 是什么,这里直接引用其他人的博客:
Valgrind是一套Linux下,开放源代码(GPL
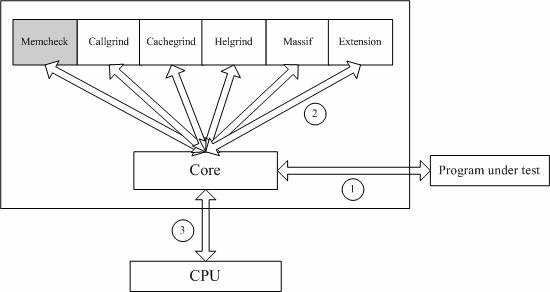
V2)的仿真调试工具的集合。Valgrind由内核(core)以及基于内核的其他调试工具组成。
内核类似于一个框架(framework),它模拟了一个CPU环境,并提供服务给其他工具;而其他工具则类似于插件 (plug-in),利用内核提供的服务完成各种特定的内存调试任务。
Valgrind的体系结构如下图所示:
Massif 命令行选项
关于 massif 命令行选项,可以直接查看 valgrind 的 help 信息:
1 |
|
对其中几个常用的选项做一个说明:
- –stacks: 栈内存的采样开关,默认关闭。打开后,会针对栈上的内存也进行采样,会使 massif 性能变慢;
- –time-unit:指定用来分析的时间单位。这个选项三个有效值:执行的指令(i),即默认值,用于大多数情况;即时(ms,单位毫秒),可用于某些特定事务;以及在堆(/或者)栈中分配/取消分配的字节(B),用于很少运行的程序,且用于测试目的,因为它最容易在不同机器中重现。这个选项在使用 ms_print 输出结果画图是游泳
- –detailed-freq: 针对详细内存快照的频率,默认是 10, 即每 10 个快照会有采集一个详细的内存快照
- –massif-out-file: 采样结束后,生成的采样文件(后续可以使用 ms_print 或者 massif-visualizer 进行分析)
开始采集
经过上面的了解,接下来可以开始内存数据采集了,假设我们需要采集的二进制程序名为 xprogram:
1 | valgrind -v --tool=massif --time-unit=B --detailed-freq=1 --massif-out-file=./massif.out ./xprogram someargs |
运行一段时间后,采集到足够多的内存数据之后,我们需要停止程序,让它生成采集的数据文件,使用 kill 命令让 valgrind 程序退出。
attention: 这里禁止使用 kill -9 模式去杀进程,不然不会产生采样文件
ms_print 分析采样文件
ms_print 是用来分析 massif 采样得到的内存数据文件的,使用命令为:
1 | ms_print ./massif.out |
或者把输出保存到文件:
1 | ms_print ./massif.out > massif.result |
打开 massif.result 看看长啥样:
1 | -------------------------------------------------------------------------------- |
这张图大概意思就表示堆内存的分配量随着采样时间的变化。从上图可以看到堆内存一直在增长,可能存在一些内存泄露等问题。
往下看还能看到内存的分配栈:
1 | 0 0 0 0 0 0 |
能看到内存分配的调用堆栈情况,据此可以看到哪里分配的内存较多。
massif-visualizer 可视化分析采样文件
ms_print 一定程度上不够直观,所以祭出另外一个分析内存采样数据的大杀器 – massif-visualizer,它能可视化的展示内存分配随着采样时间的变化情况,并能直观的看到内存分配的排行榜。
注意: massif-visualizer 目前好像只支持 linux 环境,并且具有桌面环境的 Linux. (mac/windows 的版本我没有找到)。
故我们采用 ubuntu-20.04-lts 作为分析环境。
安装软件
直接在软件中心搜索 massif-visualizer,然后安装
启动软件,分析数据
双击 massif-visualizer 启动软件之后,打开并选中某个 massif.out 文件,或者用命令行的方式打开:
1 | massif-visualizer ./massif.out |
启动后,能直观的看到内存随采样时间的变化情况:
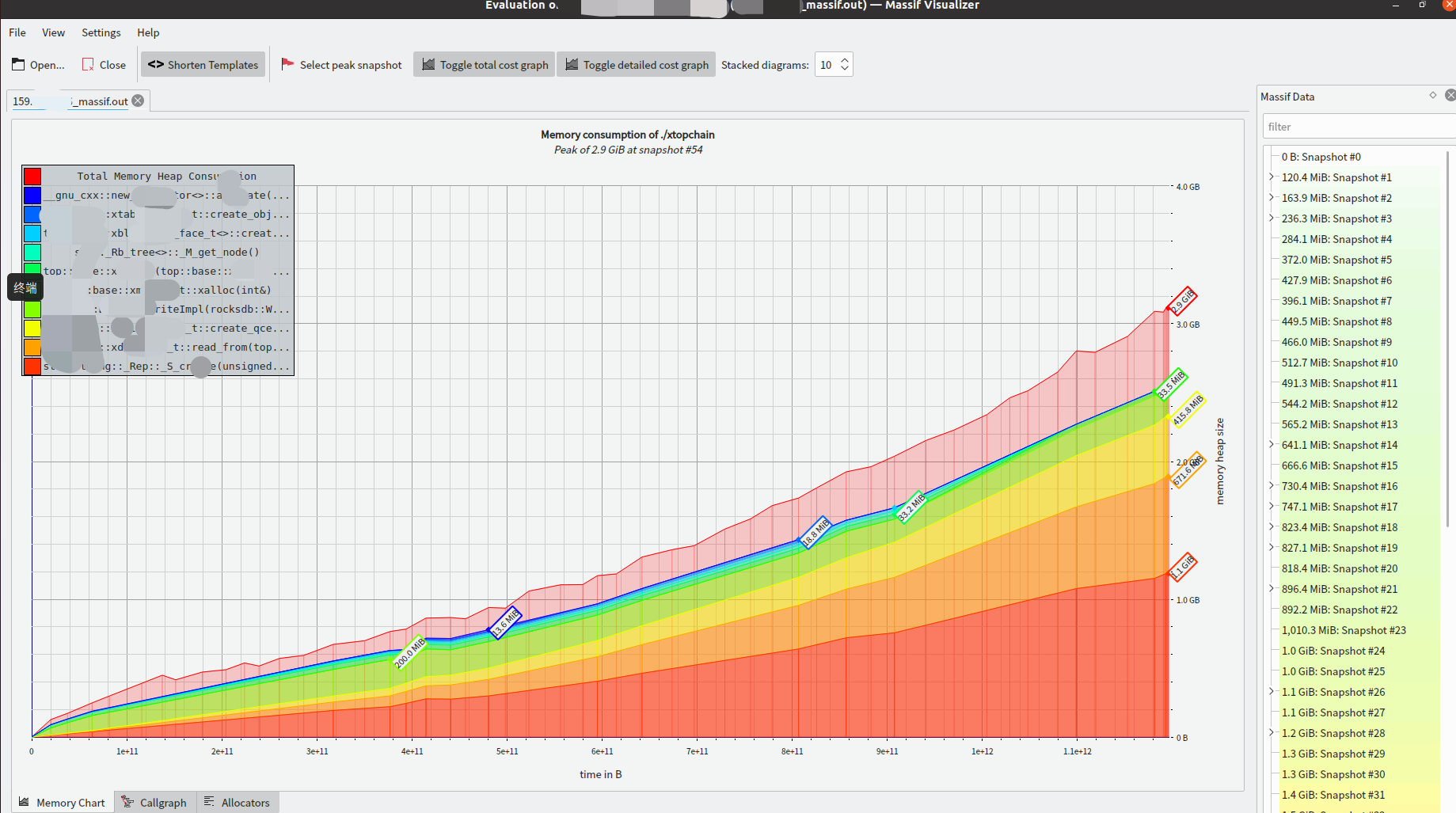
调整上面的选项 Stacked diagrams 值后:
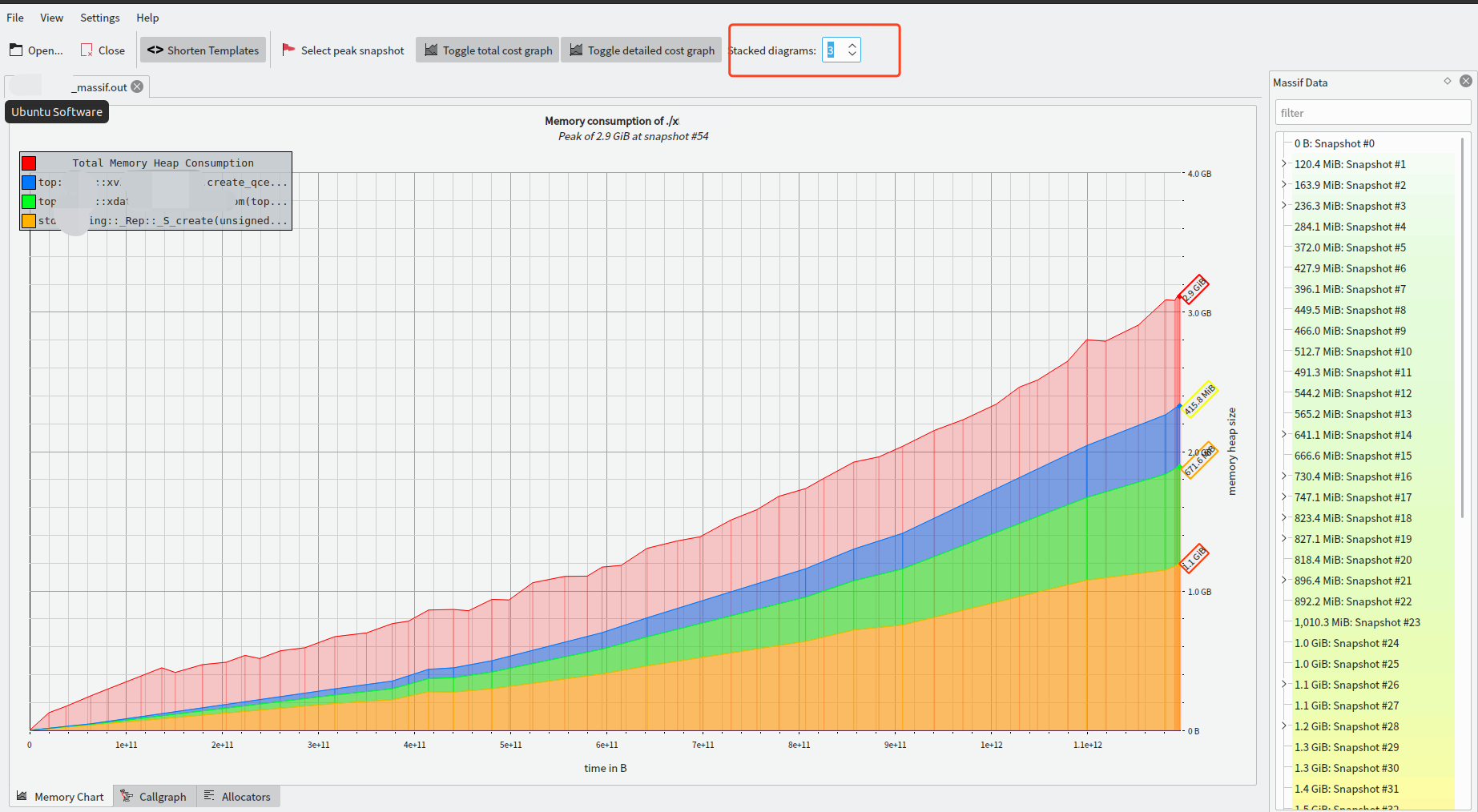
鼠标悬停之后也能看到每条曲线某个 snapshot 对应的内存分配情况。
界面右边是内存调用的堆栈:
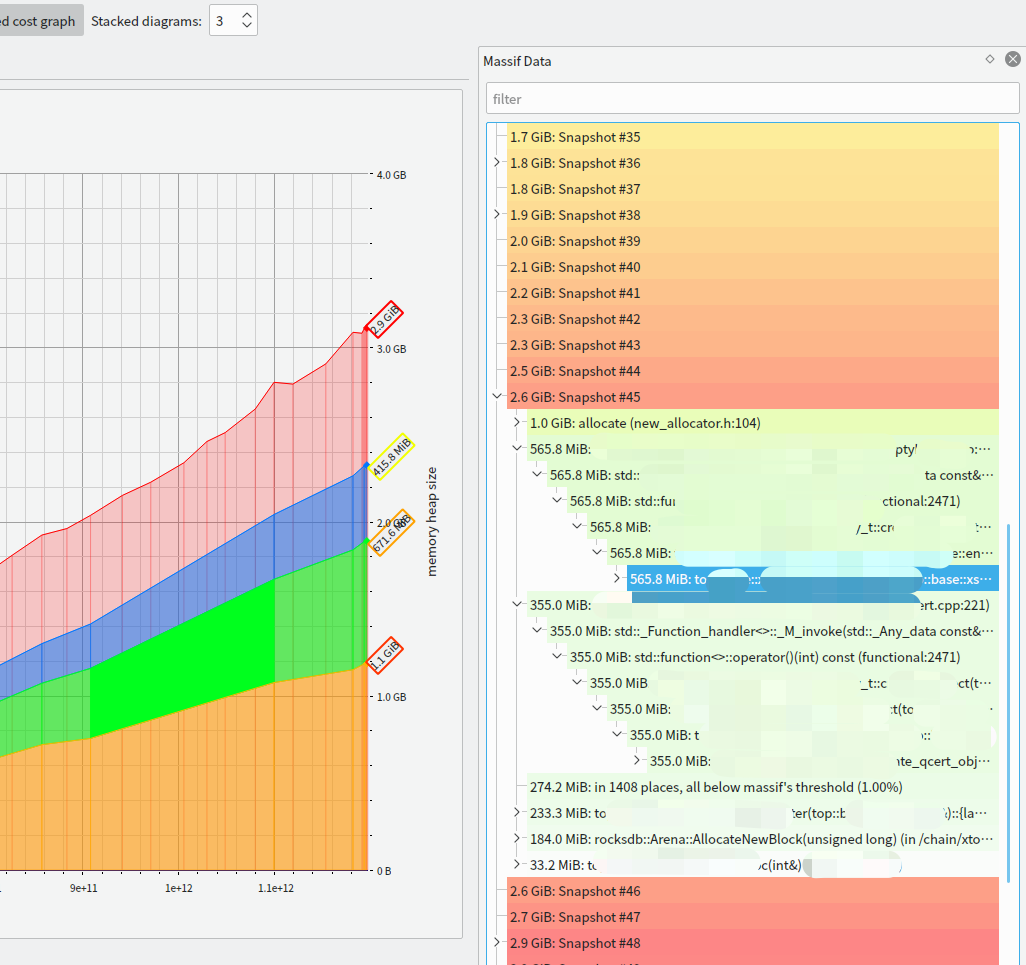
点击界面下面的 Allocators 按钮之后,可以看到内存分配的排行榜:
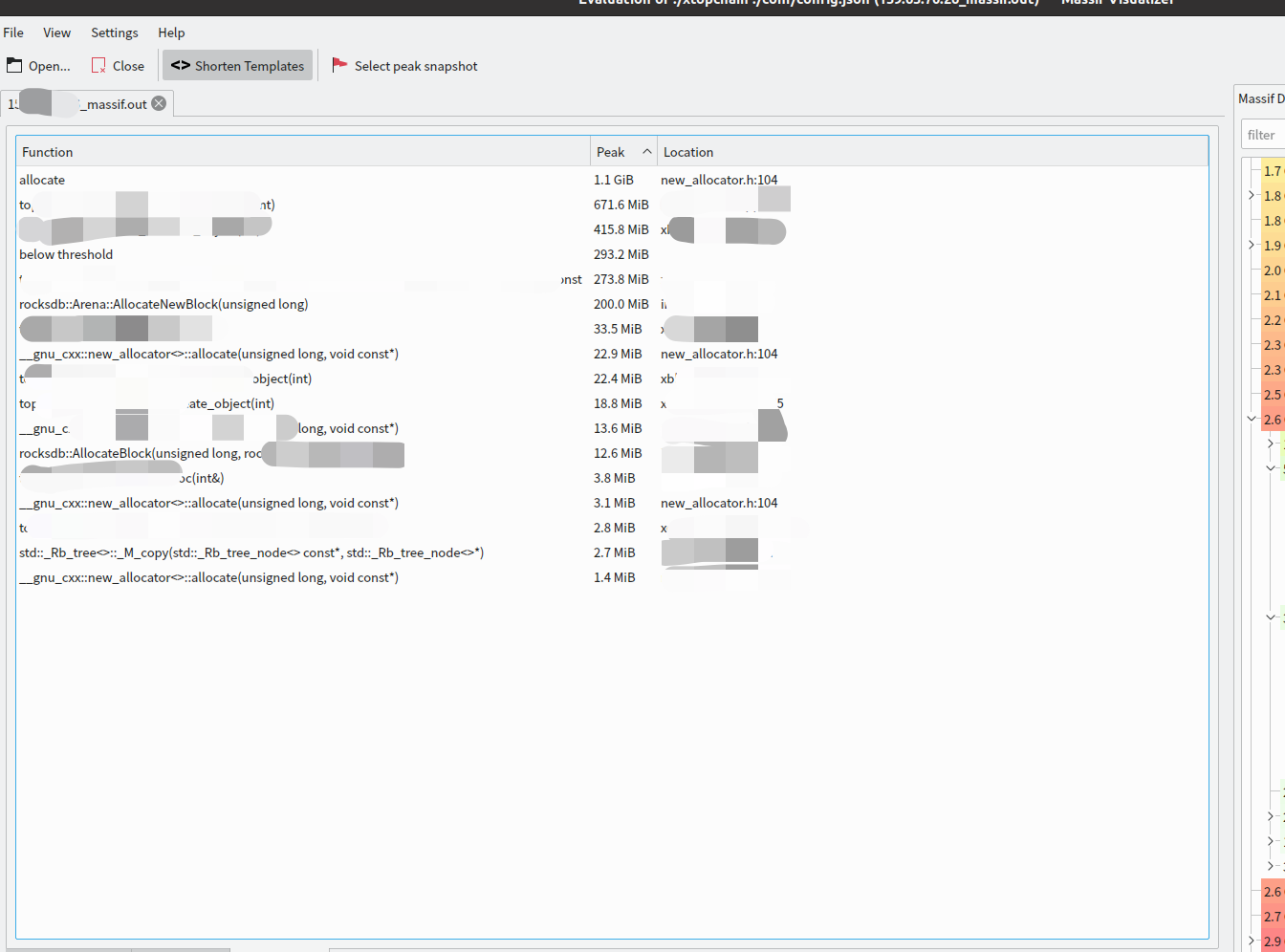
是不是很方便?
写在最后
其实用于分析内存分配情况的利器还可以采用 google-perftools,也是采用对内存采样的方式进行采集,然后生成不同的内存采样文件,结束之后比较两个内存采样文件,就可以分析内存分配情况,同时也能展示初内存分配的函数调用栈。不过相比较于 valgrind 的 massif 插件,google-perftools 是需要代码侵入的,并且不能直观的展示内存随采样时间的变化情况。
而 massif 采样的内存数据文件,借助 massif-visualizer 工具就能直观的感受到内存分配随采样时间的变化情况。
Blog:
2020-06-16 于杭州
By 史矛革
