从何说起
说起 tcp 的连接过程,想必 “3次握手4次挥手”是大家广为熟知的知识,那么关于更细节更底层的连接过程也许就很少人能讲清楚了。
所以本文会先简单回顾一下 tcp 的 3次握手过程,然后重点聊一下 tcp accept 的过程,涉及到 tcp 半连接队列、全连接队列等的内容。
回顾一下
3 次握手
要了解 3 次握手的过程,可能需要先熟悉一下 tcp 协议的格式:
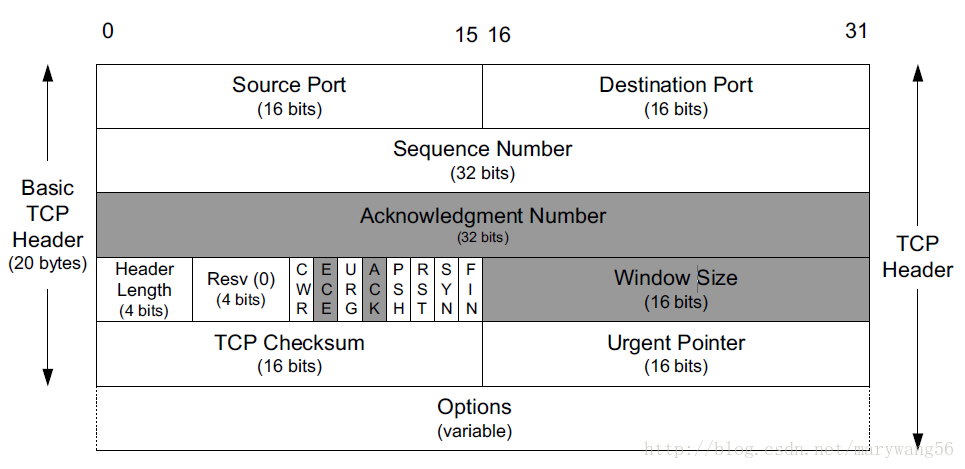
- tcp segment 的头部有两个 2字节的字段
source port和dest port,分别表示本机端口以及目标端口,在 tcp 传输层是没有 IP 的概念的,那是 IP 层 的概念,IP 层协议会在 IP 协议的头部加上src ip和dest ip; - 4 个字节的 seq,表示序列号,tcp 是可靠连接,不会乱序;
- 4 个字节的 ack,表示确认号,表示对接收到的上一个报文的确认,值为 seq + 1;
- 几个标志位:ACK,RST,SYN,FIN 这些是我们常用的,比较熟悉的。其中 ACK 简写为 “.”; RST 简写为 “R”; SYN 简写为 “S”; FIN 简写为 “F”;
注意: ack 和 ACK 是不一样的意思,一个是确认号,一个是标志位
了解了 tcp 协议的头部格式,那么再来讲一下 3 次握手的过程:
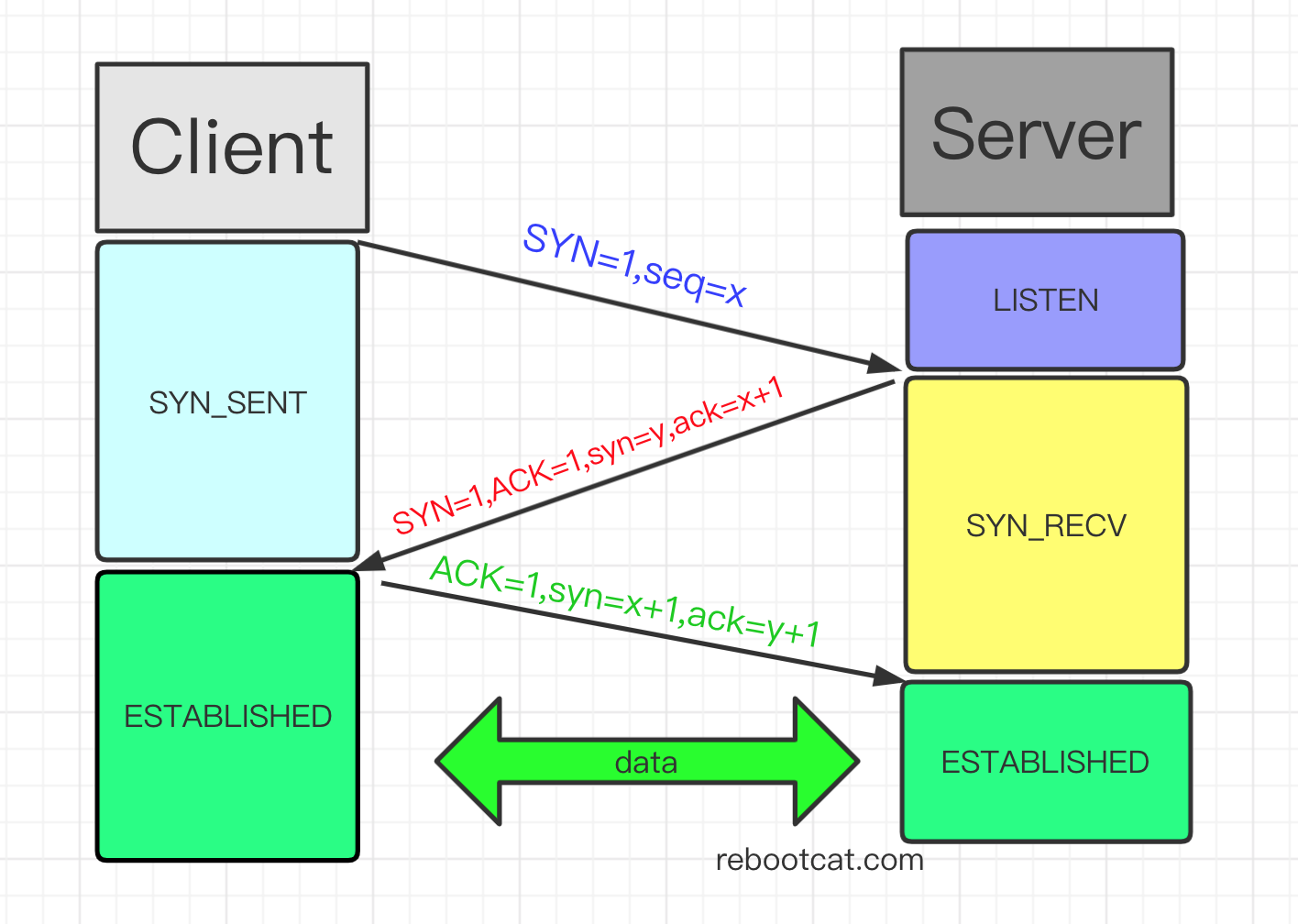
- 客户端对服务端发起建立连接的请求,发送一个 SYN 包(也就是 SYN 标志位设置为 1),同时随机生成一个 seq 值 x,然后客户端就处于 SYN_SENT 状态;
- 服务端收到客户端的连接请求,回复一个 SYN+ACK包(也就是设置 SYN 和 ACK 标志位为 1),同时随机生成一个 seq 值 y,然后确认号 ack = x + 1,也就是 client 的 seq +1,服务端进入 SYN_RECV 阶段;
- 客户端收到服务端的 SYN+ACK 包,会回复一个 ACK 包(也就是设置 ACK 标志位为 1),设置 seq = x + 1,ack 等于 服务端的 seq +1,也就是 ack = y+1,然后连接建立成功;
tcpdump 抓包
开一个终端执行以下命令作为服务端:
1 | # 服务端 |
然后打开新的终端用 tcpdump 抓包:
1 | # -i 表示监听所有网卡; |
然后再打开一个终端模拟客户端:
1 | $ nc 127.0.0.1 10000 |
观察 tcpdump 的输出如下:
1 | IP Jia.22921 > 192.168.1.7.ndmp: Flags [S], seq 614247470, win 29200, options [mss 1460,sackOK,TS val 159627770 ecr 0], length 0 |
分析以下上面的结果可以看到:
第一个包 Flags [S] 表示 SYN 包,seq 为随机值 614247470;
然后服务端回复了一个 Falgs [S.],也就是 SYN+ACK 包,同时设置 seq 为随机值 1720434034,设置 ack 为 614247470 + 1 = 614247471;
客户端收到之后,回复一个 Flags [.],也就是 ACK 包,同时设置 ack 为 1720434034 + 1 = 1720434035;
假如3次握手丢包了?
上面是正常情况的握手情况,假如握手过程中的任何一个包出现丢包呢会怎么样?比如受到了攻击,比如服务端宕机,服务端超时,客户端掉线,网络波动等。
所以接下来我们分析下 3 次握手过程中涉及到的连接队列。
tcp 内核参数
backlog 参数
https://linux.die.net/man/3/listen
The backlog argument provides a hint to the implementation which the implementation shall use to limit the number of outstanding connections in the socket’s listen queue. Implementations may impose a limit on backlog and silently reduce the specified value. Normally, a larger backlog argument value shall result in a larger or equal length of the listen queue. Implementations shall support values of backlog up to SOMAXCONN, defined in <sys/socket.h>.
1 | int listen(int socket, int backlog); |
backlog 参数是用来限制 tcp listen queue 的大小的,真实的 listen queue 大小其实也是跟内核参数 somaxconn 有关系,somaxconn 是内核用来限制同一个端口上的连接队列长度。
全连接队列
完成 3 次握手的连接,也就是服务端收到了客户端发送的最后一个 ACK 报文后,这个连接会被放到这个端口的全连接队列里,然后等待应用程序来处理,对于 epoll 来说就是内核触发 EPOLLIN 事件,然后应用层使用 epoll_wait 来处理 accept 事件,为连接分配创建 socket 结构,分配 file descriptor 等;
那么假如应用层没有来处理这些就绪的连接呢?那么这个全连接队列有可能就满了,导致后续的连接被丢弃,发生全连接队列溢出,丢弃这个连接,对客户端来说就无法成功建立连接。
所以为了性能的考虑,我们有必要尽可能的把这个队列的大小调大一点。
查看全连接队列大小
可以通过一下命令来查看当前端口的全连接队列大小:
1 | $ ss -antl |
在 ss 输出中:
LISTEN 状态:Recv-Q 表示当前 listen backlog 队列中的连接数目(等待用户调用 accept() 获取的、已完成 3 次握手的 socket 连接数量),而 Send-Q 表示了 listen socket 最大能容纳的 backlog。
非 LISTEN 状态:Recv-Q 表示了 receive queue 中存在的字节数目;Send-Q 表示 send queue 中存在的字节数;
压测观察全连接队列溢出
接下来我们实际测试一下,使用项目:mux。
我们先修改一下 backlog 参数为 5:
1 | # 把backlog 调小一点 |
根据编译文档,编译后得到两个二进制:
1 | $ ls |
bench_server用来作为服务端,底层使用 epoll 实现bench_client_accept作为压测客户端,并发创建大量连接,这里只会与服务端建立连接,不会发送其他任何消息(当然可以用其他的压测工具)
选择两台机器进行测试,192.168.1.7 作为服务端, 192.168.1.4 作为压测客户端,开始压测前,可能需要设置一下:
1 | ulimit -n 65535 |
1) 启动服务端
1 | # 192.168.1.7 作为服务端,监听 10000 端口 |
注意到上图执行 ss -antl 看到 10000 端口的 listen queue size 为 5,这里是故意调小一点,为了验证全连接队列溢出的场景。
2) 先观察一下服务端全连接队列的情况以及溢出的情况
1 | $ ss -natl |grep 10000 |
上述表明 10000 端口的 listen queue size 为 5,并且全连接队列中没有等待应用层处理的连接;
netstat -s |grep -i overflowed 表示全连接队列溢出的情况,2683 是一个累加值。
2) 启动 tcpdump 对客户端行为抓包,分析 3次握手连接情况
1 | # 运行在 client: 192.168.1.4 上 |
3)启动压测客户端
1 | # 192.168.1.4 作为压测客户端 |
压测过程中,可以不断执行命令观察服务端全连接队列溢出的情况,压测完毕之后再观察一下全连接队列溢出的情况:
1 | $ ss -natl |grep 10000 |
可以看到,压测过程中的 Recv-Q 出现了5,1 的值,表示全连接队列中等待被处理的连接,而且有 2930 - 2283 = 647 次连接由于全连接队列溢出而被丢弃。
我们再来观察一下 bench_client_accept 的日志情况:
1 | $ grep -a 'Start OK' log/bench_client_accept.log |wc -l |
可以看到最终有 264 个 client 由于服务端丢弃建立连接时 3 次握手的包而造成连接失败。
如果你细心的话会发现,全连接队列溢出发生了 647 次,但是最终只有 264 个 client 建立失败,why?其实原因很简单,因为客户端有重试机制,具体参数是 net.ipv4.tcp_syn_retries,这个暂且不详说。
那再来看一下 tcpdump 抓包的结果,这里要用到一个 python 脚本 tcpdump_analyze.py 来处理一下 tcpdump.log 这个日志:
1 | import os |
运行后得到结果:
1 | $ python tcpdump_analyze.py |
上面的意思是总共有 29736 个 client 成功建立连接,而有 264 个 client 建立失败;连接成功的 client 里有 29195 个是通过了正常的 3 次握手成功建立,没有发生重试;而有 541 个 client 是发生了重试的情况下才建立连接成功。
可以看到上面的输出,发生重试 “succ with retry” 的部分,client 发送一个 SYN 之后,由于 server 全连接队列溢出导致连接被丢弃,client 超时后重新发送 SYN 包,然后建立连接;
而上面连接失败的客户端,错误原因都是: errno = 110,也就是 “Connection timed out”。
Ok,到现在应该明白全连接队列大小对于 tcp 3 次握手的影响,如果全连接队列过小,一旦发生溢出,就会影响后续的连接。
调整内核参数,避免全连接队列溢出
那我们修改一下 backlog 的大小,改大一些:
1 | listen(listenfd, 100000); |
然后我们修改内核参数:
1 | net.core.netdev_max_backlog = 400000 |
可以通过打开 /etc/sysctl.conf 直接修改,或是通过命令修改:
1 | $ sysctl -w net.core.netdev_max_backlog=400000 |
重新编译运行,执行上述的压测,观察结果。
压测前:
1 | $ ss -natl |grep 10000 |
压测后:
1 | $ netstat -s |grep -i overflowed |
可以看到,当我们把内核参数以及 backlog 调大之后,30000 个 client 全部建立连接成功且没有发生重试,服务端的 listen queue 没有发生溢出。
半连接队列
全连接队列存放的是已经完成 3次握手,等待应用层调用 accept() 处理这些连接;其实还有一个半连接队列,当服务端收到客户端的 SYN 包后,并且回复 SYN+ACK包后,服务端进入 SYN_RECV 状态,此时这种连接称为半连接,会被存放到半连接队列,当完成 3 次握手之后,tcp 会把这个连接从半连接队列中移到全连接队列,然后等待应用层处理。
那么怎么查看半连接队列的大小呢?没有直接的 linux command 来查询半连接队列的长度,但是根据上面的定义,服务端处于 SYN_RECV 状态的数量就表示半连接的数量。所以采用一定的方式增大半连接的数量,看服务端 SYN_RECV 的数量最大值有多少,那就是半连接队列的大小。
那问题就来了,如何增大半连接的数量呢?这里采用到的就是 SYN-FLOOD 攻击,通过发送大量的 SYN 包而不进行回应,造成服务端创建了大量的半连接,但是这些半连接不会被确认,最终把 tcp 半连接队列占满造成溢出,并影响正常的连接。
半连接队列溢出
采用的工具是: hping3,一款很强大的工具。
启动服务端:
1 | # 192.168.1.7 作为服务端,监听 10000 端口 |
开始攻击:
1 | $ hping3 -S --flood --rand-source -p 10000 192.168.1.7 |
观察半连接数量:
1 | $ netstat -ant |grep SYN |
持续观察,可以看到处于 SYN_RECV 状态的连接基本保持在 256,说明半连接队列的大小是 256。而此时,10000 端口已经比较难连接上了。
查看一下半连接队列的丢弃情况:
1 | $ netstat -s |grep dropped |
注意: 26055883 是一个累加值,可以持续观察
那怎么增大半连接队列大小呢?
增大半连接队列,防止溢出
直接修改内核参数:
1 | # 直接修改文件 /etc/sysctl.conf |
或者使用命令:
1 | $ sysctl -w net.ipv4.tcp_max_syn_backlog=100000 |
据说半连接队列并非只由这个参数决定,不同的系统的计算方式不一致,还会和全连接队列大小有关
当然这个应对 SYN-Flood 攻击只是轻微降低影响而已。
还可以设置 net.ipv4.tcp_syncookies = 0 来一定程度防范 SYN 攻击。
syncookies 的原理就是当服务端收到客户端 SYN 包后,不会放到半连接队列里,而是通过 {src_ip, src_port, timestamp} 等计算一个 cookie(也就是一个哈希值),通过 SYN+ACK包返回给客户端,客户端返回一个 ACK 包,携带上这个 cookie,服务端通过校验可以直接把这个连接放入全连接队列。整个过程不需要半连接队列的参与。
SYN 重试
上面压测验证全连接队列溢出的场景下,通过 tcpdump 抓包分析到有些连接是经过了重试才建立成功的,具体表现在:
客户端发送 SYN 包请求建立连接,但此时由于服务端全连接队列溢出或者半连接队列溢出,该 SYN 包就会被丢弃,当客户端迟迟无法收到服务端的 SYN+ACK 包后,客户端超时重发 SYN 包,如果再次超时,那么根据内核设置的 SYN 超时重试次数决定是否继续重发 SYN 包。
假设重试次数为 6 次:
- 第一次发送 SYN 后等待 1 s (2^0);
- 第二次发送 SYN 后等待 2 s (2^1);
- 第三次发送 SYN 后等待 4 s (2^1);
- …
所以当我们发现服务端出现了问题的时候,可以适当提高 SYN 重试的次数;当然过大的值也会影响问题的快速发现;
可以通过设置:
1 | $ sysctl -w net.ipv4.tcp_syn_retries=2 |
The End
Ok, 到这里基本上把 tcp 3 次握手比较细节的地方讲到了。 tcp 真是一个巨复杂的协议,还有不少值得深挖的东西!
Blog:
2020-11-14 于杭州
By 史矛革
