前言
上一篇博文 Epoll原理深入分析 在讲 accept 事件 的时候提到过 惊群效应,本文就分析一下惊群效应的原因以及解决方法。
惊群效应
什么是惊群
惊群效应就是多个进程(线程)阻塞等待同一件事情(资源)上,当事件发生(资源可用)时,操作系统可能会唤醒所有等待这个事件(资源)的进程(线程),但是最终却只有一个进程(线程)成功获取该事件(资源),而其他进程(线程)获取失败,只能重新阻塞等待事件(资源)可用,但是这就造成了额外的性能损失。这种现象就称为惊群效应。
如果细心的你可能会问,为什么操作系统要同时唤醒多个进程呢?只唤醒一个不行吗?这样不就没有这种性能损失了吗?
确实如此,操作系统也想只唤醒一个进程,但是它做不到啊,因为它也不知道该唤醒哪一个,只好把所有等待在这件事情(资源)的进程都一起唤醒了。
那有没有办法解决呢?当然有,我们后面再说。
惊群效应会造成多个进程白白唤醒而啥也做不了。那么唤醒进程损失了啥?这就涉及到进程上下文的概念。
惊群造成进程切换
进程上下文包括了进程的虚拟内存,栈,全局变量等用户空间的资源,还包括内核堆栈,寄存器等内核空间的状态。
所以进程上下文切换就首先需要保存用户态资源以及内核态资源,然后再去加载下一个进程,首先是加载了下一个进程的内核态,然后再去刷新进程的用户态空间。
然而 CPU 保存进程的用户态以及内核态资源,再去加载下一个进程的内核态和用户态是有代价的,也是耗时的,每次可能在几十纳秒到数微妙的时间,如果频繁发生进程切换,那么 CPU 将有大量的时间浪费在不断保存资源,加载资源,刷新资源等事情上,造成性能的浪费。
所以惊群效应会造成多个进程切换,造成性能损失。
惊群测试
为了直观的了解惊群效应是什么,我们采用 mux 项目当中的 echo_server 为例说明:
https://github.com/smaugx/mux/tree/master/demo/echo
编译命令详见项目说明文档。编译之后得到:
1 | echo_server echo_client |
我们在 echo_server 上开启 8 个 epoll 线程,观察当有新连接过来时是否这 8 个线程(epoll) 都被唤醒了。
首先,运行:
1 | ./echo_server |
再运行:
1 | ./echo_client (或者直接用 nc 127.0.0.1 6666) |
我们观察的 echo_server 的 log 如下:
1 | smaug@smaug-VirtualBox:~/workspace/mux/cbuild/bin/log$ tail -f echo_server.log |grep accept |
从上可以看到,我们总共有 8 个线程,其中只有 3号线程(epoll)被唤醒并且成功获取了 accept 事件,其他线程均 accept error。
多次测试会有不同的线程获取 accept 事件,但是只有一个能够成功获取,其余的全部失败。
为了更加直观的感受惊群造成的性能损失,我们做一个并发压测:
https://github.com/smaugx/mux/tree/master/demo/bench
编译上面的代码得到:
1 | bench_client_accept bench_server |
首先,启动:
1 | ./bench_server 127.0.0.1 10000 > /dev/null 2>&1 & |
再启动:
1 | ./bench_client_accept 127.0.0.1 10000 30000 100 > /dev/null 2>&1 & |
使用之前的博文 一键采集cpu生成火焰图 中的脚本采集火焰图如下:
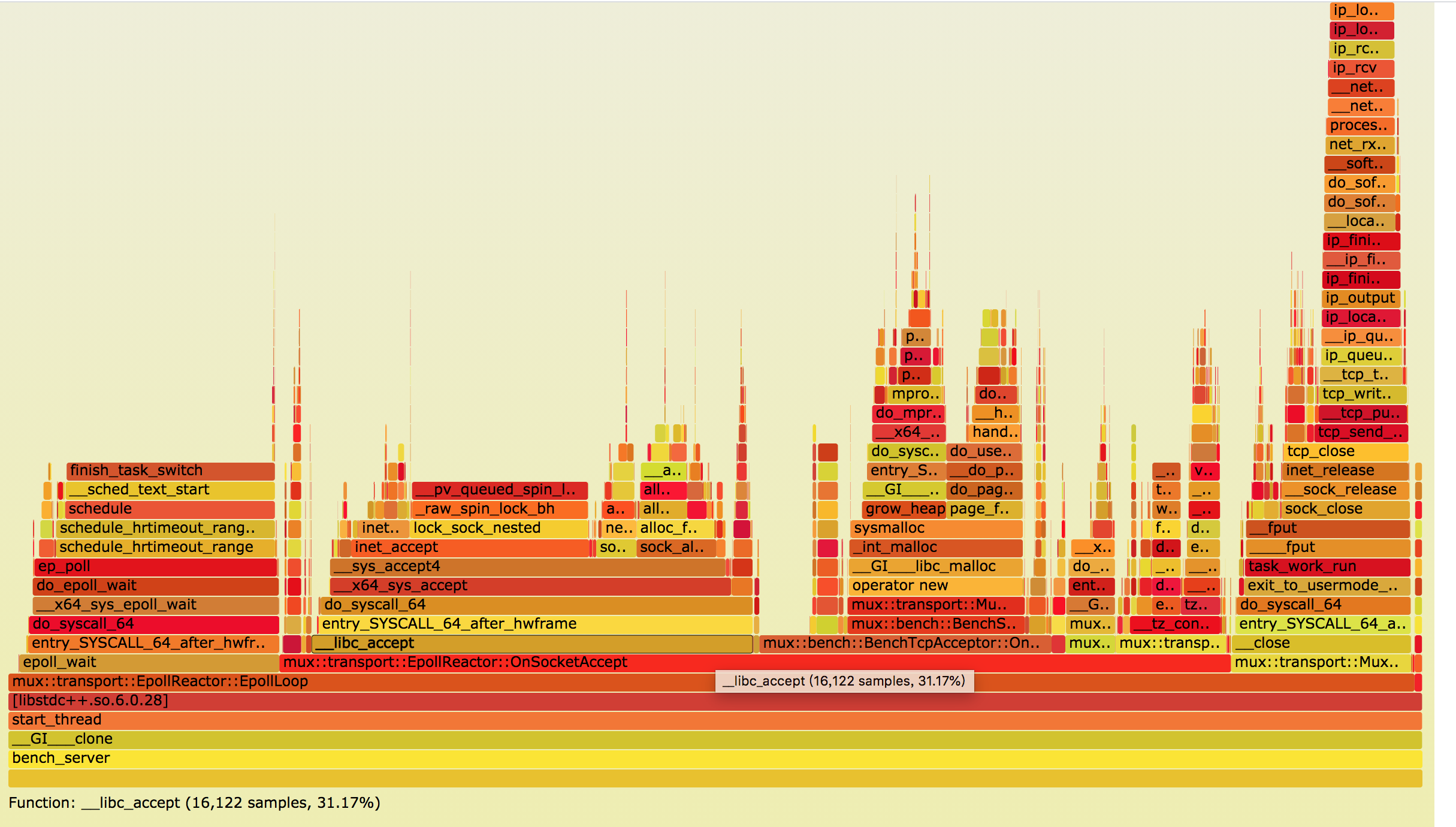
可以看到途中 __libc_accept 占据了 31.7% 的 cpu,可以说是很高很高了。
由此可以看到惊群效应带来的性能损失有多少了吧。
惊群的类型
惊群的类型根据 socket 编程采用的不同方式有关。
传统 accept 惊群
传统的多进程 socket 编程,通常是 listen() 之后创建多个 worker 进程进行 accept,那么这里就会造成当有新连接过来时,多个 worker 同时去 accept 的情况,但最终只有一个 worker 进程成功 accept,其余的全部失败。
1 | ... |
此种情况下的惊群称为 accept惊群效应,这在 linux 内核2.6以后就已经解决了,所以通常情况下讨论的惊群通常不是 accept惊群,而是 epoll惊群。
epoll 惊群
epoll 的编程模型一般有两种,我们姑且先分别称为 版本1 和 版本2 吧:
1 | int listenfd = ::socket(); |
或者 fork() 在 epoll_create() 之前:
1 |
|
虽然上述两个版本均能实现多进程下的 epoll 编程,且都存在惊群效应,但版本1,也就是 fork() 在 epoll_create() 之后会造成事件混乱。
因为多个进程等待的是同一个 epollfd,就有可能造成同一个连接,worker A 获取了 accept 事件,成功建立了连接,但是后续的读事件被 worker B 获取了,造成连接和读写事件不匹配的情况。
所以通常,我们采用的是版本2,也就是 fork() 在 epoll_create() 之前,那么多个子进程其实是拥有各自不同的 epollfd,只不过对于 listenfd 而言,都被添加到了各个子进程的 epoll instance 中。
当 listenfd 上有事件触发时(listenfd 上的事件自然是 accept 事件),由于有多个子进程的 epoll instance 上都有 listenfd。
根据之前的博文 Epoll原理深入分析,当某个 fd 上有事件后,内核会把这个 fd 拷贝到 epoll 的就绪链表中,并且唤醒进程,通知应用层使用 epoll_wait 来处理事件。
所以由于多个子进程都把 listenfd 插入到了自己的 epoll instance 中,那么当 listenfd 上有事件触发时,自然这些子进程都会被唤醒了。但是最终只有一个子进程成功获取 accept 事件,其余的均失败。这就是惊群效应,详见上面的惊群效应测试。
解决方案
传统 accept 惊群
上面提到,针对传统 accept 惊群,linux 在内核 2.6 以后就解决了,内核通过引入一个 WQ_FLAG_EXCLUSIVE 标志位,告诉内核排他性的唤醒,即当 socket 上有事件触发时,对于等待队列中的进程,如果这些进程没有 WQ_FLAG_EXCLUSIVE 这个标志位,那么就通通唤醒,如果有 WQ_FLAG_EXCLUSIVE 这个标志位,那么唤醒第一个有这个标志位的进程则结束。这样,就解决了传统 accept 惊群问题。
epoll 惊群
epoll 的惊群有两种解决办法。
SO_REUSEPORT
linux 在内核 3.9 版本引入了一个 socket 选项 SO_REUSEPORT 用来支持多个进程监听在同一个端口上,内核负责事件触发的负载均衡。
创建一个 listen socket,需要 {protocol, src_addr, src_port} 三元组,3.9 版本之前,内核不允许出现多个进程使用同样的三元组创建 socket,会出现 Address already in use 错误。
但是,通过引入 SO_REUSEPORT 以及 SO_REUSEADDR,内核允许多个进程使用同样的三元组创建 socket,内核负责负载均衡。
ok,明白了这个原理,对于解决 epoll 的惊群问题,还需要稍微修改一下编程的模型,我们姑且成为 版本3 吧:
1 |
|
可以对比一下和上面的编程模型有何不同,其实区别在创建 listenfd 被移到了 fork() 之后,程序启动即创建多个进程,然后进程内部再创建 listenfd 以及 epollfd,等等后续一系列操作。
另外要注意在 socket() 之后,使用 setsockopt() 设置了 SO_REUSEPORT 选项。
那么内核是如何做负载均衡的呢?
其实很简单,每一个新的连接都具有 socket 五元组 {protocol, src_addr, src_port, dst_addr, dst_port},那么用这个五元组哈希一下映射到不同的进程,那么就唤醒这个进程。
SO_REUSEPORT 由于采用的是哈希的方式,内核并不知道多个等待进程是否空闲,但哈希的方式依然可能还会分配到这个进程,此时这个新的 accept 就可能会超时不被处理。
EPOLLEXCLUSIVE
linux 在内核 4.5 引入了 EPOLLEXCLUSIVE 这个标志位用来解决 epoll 的惊群。当我们使用 epoll_ctl() 往进程的 epoll instance 中插入一个需要监听的 fd 时,如果显示的传入 EPOLLEXCLUSIVE,那么内核会排他性的进行唤醒。
当然这里通常只需要对多个子进程共同监听的 listenfd 设置 EPOLLEXCLUSIVE 标志位。注意,这里的 epoll 编程模型要采用上面的版本2。
和解决传统 accept惊群 类似的方式,但是区别是内核可能会唤醒不只一个进程(虽然解决了不全部唤醒的问题),详见:
https://man7.org/linux/man-pages/man2/epoll_ctl.2.html
1 | When a wakeup event occurs and multiple epoll file descriptors |
注意上面的 one or more
The END
OK,到这里基本上把惊群效应的原理以及带来的问题,以及解决方法都讲清楚了,本来还想做一个加上了 EPOLLEXCLUSIVE,再采集一下火焰图和之前的进行一下对比,但是不知道是我的方式不对还是什么原因,加上 EPOLLEXCLUSIVE 标志后,连接压力测试就池池上不去,一直出现 connection timeout 的问题。
算了,这个以后再研究下为啥。
如果上文发现有什么不对的地方,欢迎指正。
Blog:
2020-09-26 于杭州
By 史矛革
