惯例闲聊
现在是杭州的冬天,鼻炎让我一直难受,特别不舒服,鼻子快被我拧坏了,最近过的也很糟心,各种烦心事,几乎一周一件烦心事甚至一周好几件烦心事,最近过得感觉很不好!以前我感觉我自己很潇洒,很酷,现在越来越发现我不酷了,连自身形象我都懒得去整理了,胡子一周不想剃,衣服放一周不想洗,头发每天乱糟糟的,几乎每天都不敢去看镜子了。
真的很不喜欢冬天!不喜欢冷!不喜欢浑浑噩噩!不喜欢越来越没激情!
这已经是2017年的最后一个月了,回想年初定下的目标,几乎没有一件事达成或满意,一直想学的茶道一直也没去做,茶具也没买,骑车这件大事也慢慢落下了,身体也慢慢垮了,唯一感觉工作本身成长很大,这样下去不行的!
好了,废话不多说,这篇博文是完完全全的工作内容,所以内容会很技术,很严肃很干货。
问题提出
为了精细化提高 nginx(marxxx) 的性能, 现分析写日志对于请求的影响。
- 条件
- 日志大小为 500 字节
- 响应大小 111 字节
- 除日志外 nginx 服务不进行任何 io 操作,使用 nginx 语法直接返回响应
- 变量
- qps服务压力了决定的磁盘承受的写日志的压力
- request time分布
- nginx log buffer: 分别测试 log buffer 为 4k, 64k, 128k 以及关闭log的情况
探究结论
1 . 关闭日志与否
开启log的情况下,request time波动明显,也即nginx提供服务的功率不稳定;而关闭日志后,request time波动微小,几乎可以忽略,也即nginx能提供更为稳定的服务,说明写日志操作对nginx的输出功率的稳定性具有关键性影响。因此线上的服务,对于要求较为苛刻的大客户可以考虑关闭日志,提供更为稳定更为高性能的服务。
2 . log buffer的大小
探究过程中发现log buffer 分别为4k、64k、128k下,nginx的性能表现不同,log buffer 为 64k 情况下表现相对更优,这里的表现指qps相对更高,request time相对更低。关于该条结论更为详细的探究将在(二)中描述。
另外,log buffer调大对cpu利用率下降,大约下降 0% ~ 5%。
3 . 磁盘压力
整体来看,记录日志导致的磁盘压力并没有很高,但不同的log buffer磁盘压力不一样。
探究过程
说明
由于条件的限制,在响应为 111 字节(实际情况为132字节),request time很小,几乎都是0ms、1ms,对后面分析不利,故调整了ngxin.conf的配置,使用连续多跳的机制,比如从 8088 端口,到 8089 再到 8090 再到8091 …最后返回。这样增大了request time的同时避免了其他的任何IO操作。
故下文会出现4k8j,64k8j的字样,代表的意思如下:
- 4K8j: 表示log buffer为 4k,在ngxin内部经过了 8 个端口(8 jump)
- 64k8j: 表示log buffer为 64k,在nginx内部经过了 8 个端口(8 jump)
- 128K8j: 表示log buffer为 128k,在ngxin内部经过了 8 个端口(8 jump)
- 128k2j: 表示log buffer为 128k,在nginx内部经过了 2 个端口(2 jump)
- off8j: 表示关闭了log,在nginx内部经过了 8 个端口(8 jump)
- off8jvx: 表示关闭日志后,调整了其他变量再次进行研究,简单理解为第几版本
探究方法
1 . 使用小米监控,编写脚本采集不同条件下的指标(精度有限,只做参考)
- nginx status 开启,编写小米监控脚本收集连接数,请求数等,目标指标是nginx的qps
- 编写小米监控脚本计算nginx平均每个worker占用的cpu(%)情况
- request time的采集使用抽样方式,每分钟取access.log的后1000条日志计算平均request time
2 . 搭建nginx,收集压测日志
- 使用wrk压测,结合lua脚本。lua脚本功能是当关闭日志后通过nginx 将request time写到响应头(body 132字节,忽略body发送时间),分析每次请求的响应头过滤request time
1 | nohup wrk -c 100 -t 8 -d20m http://127.0.0.1:8088 -s /disk/ssd1/ngx/benchngx_logoff.lua > /dev/null & 2>&1 |
- 使用ab压测,排除压测客户端本身带来的影响,比如提供http请求的稳定度
1 | ab -n 5000000 -c 8 -v 3 -k http://127.0.0.1:8088/ |grep 'X-Time' |cut -d ' ' -f 2,3,4 >> off8jv13.a |
- 分析大量日志,计算指标间关系,绘制关系图。使用到python/redis/highcharts
探究过程记录
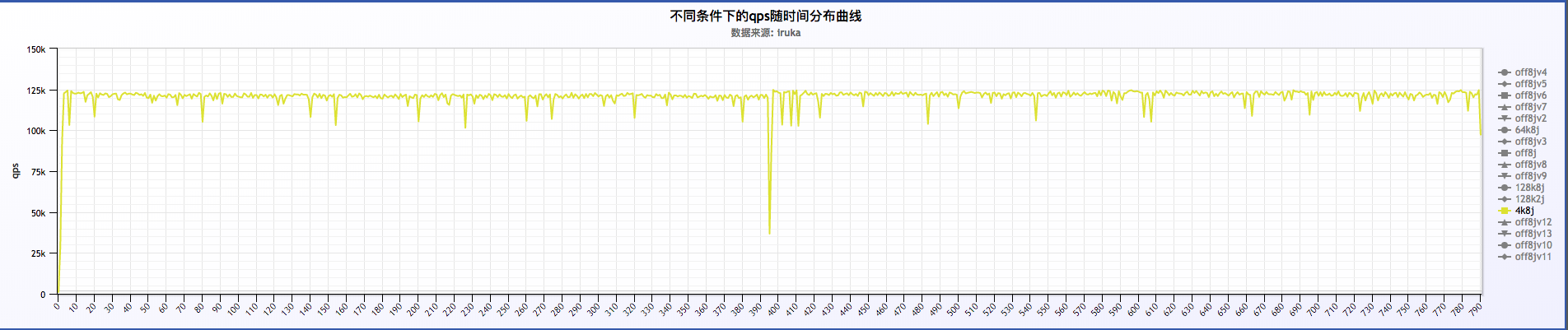
1 . log buffer = 4k && 8 jump
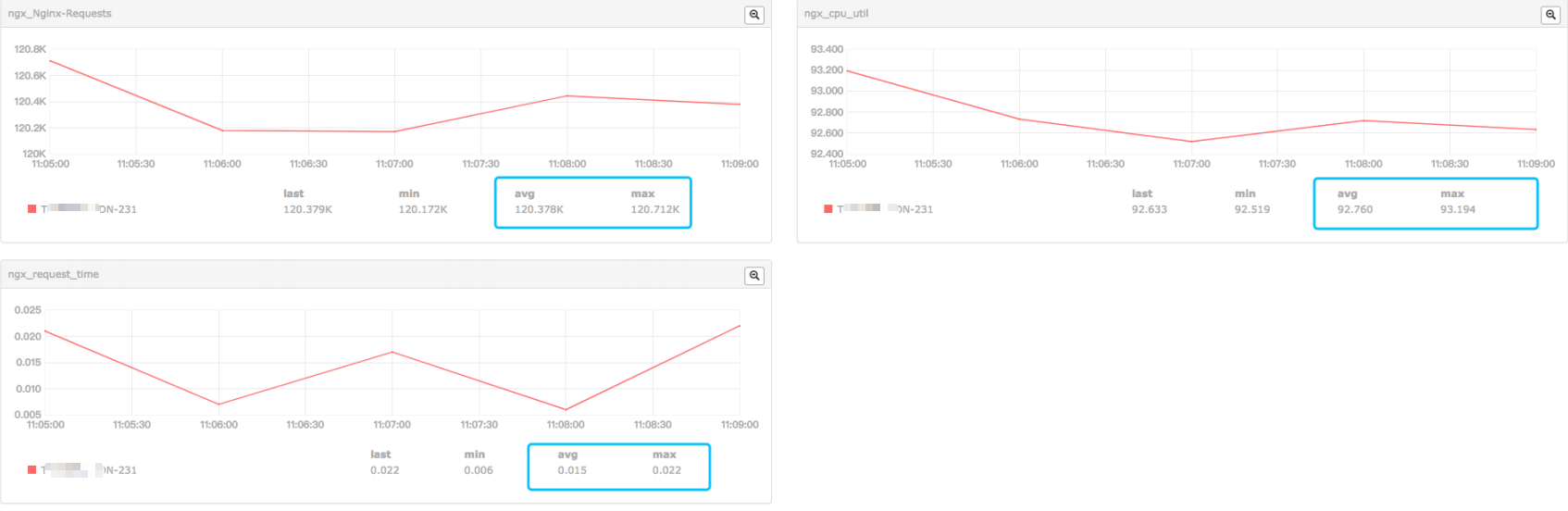
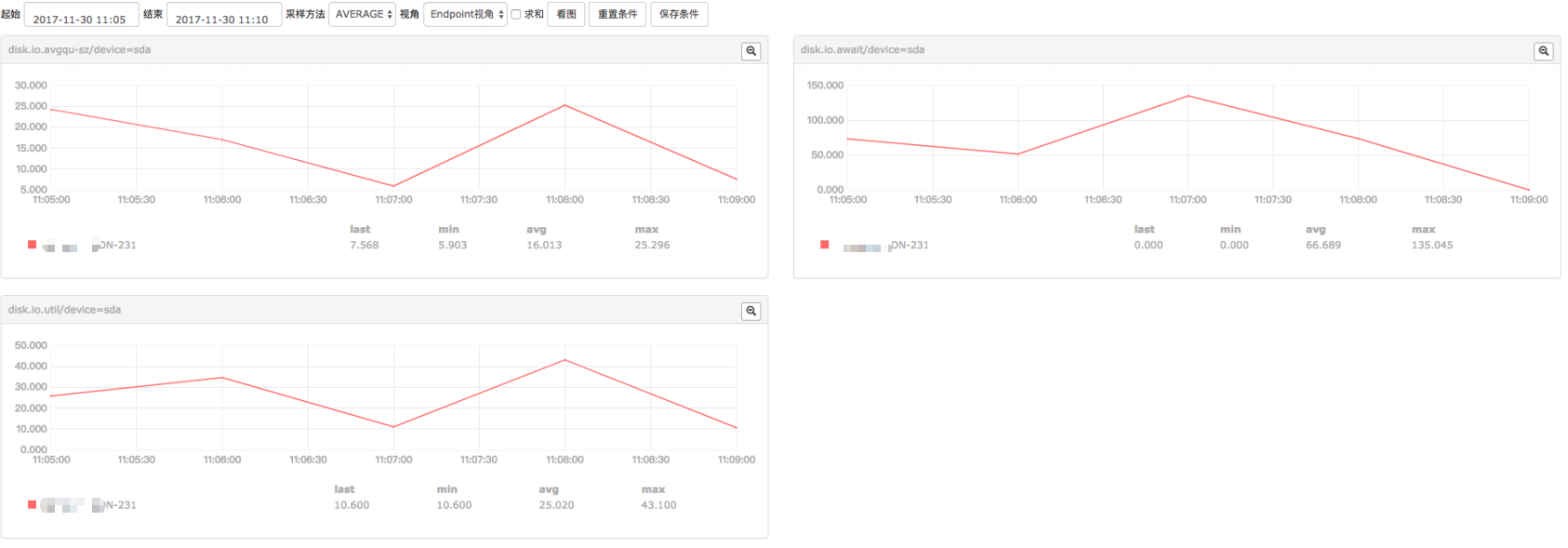
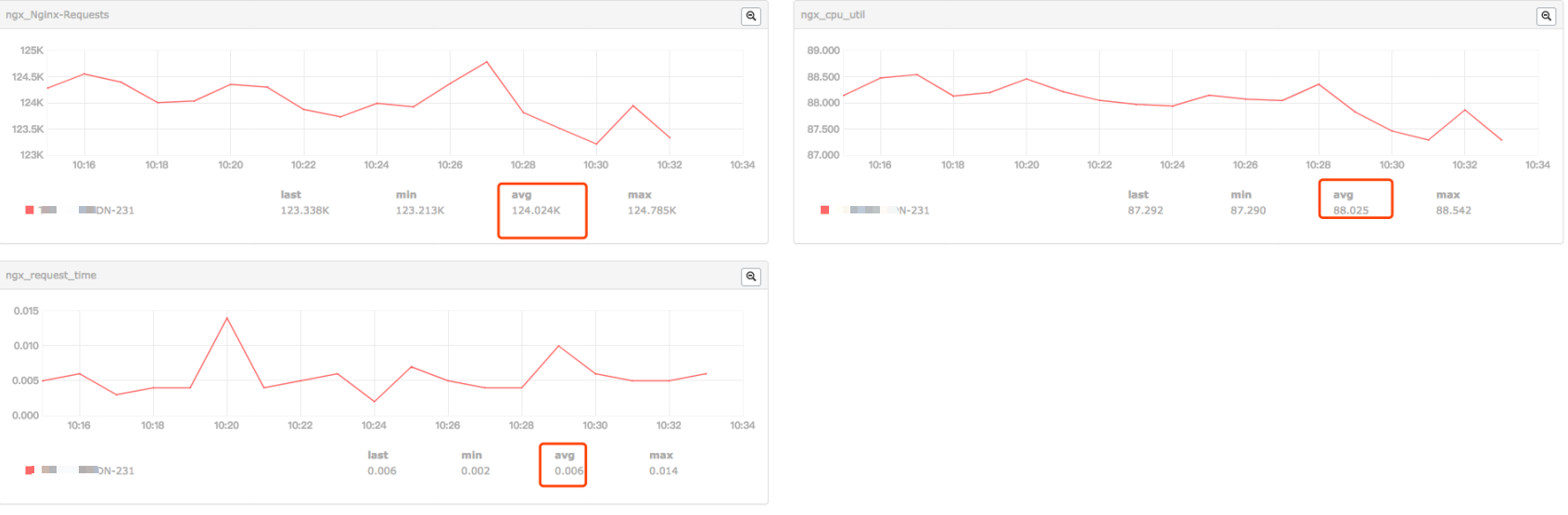
小米监控的结果(qps,cpu,request time,磁盘指标)
日志分析
局部放大后: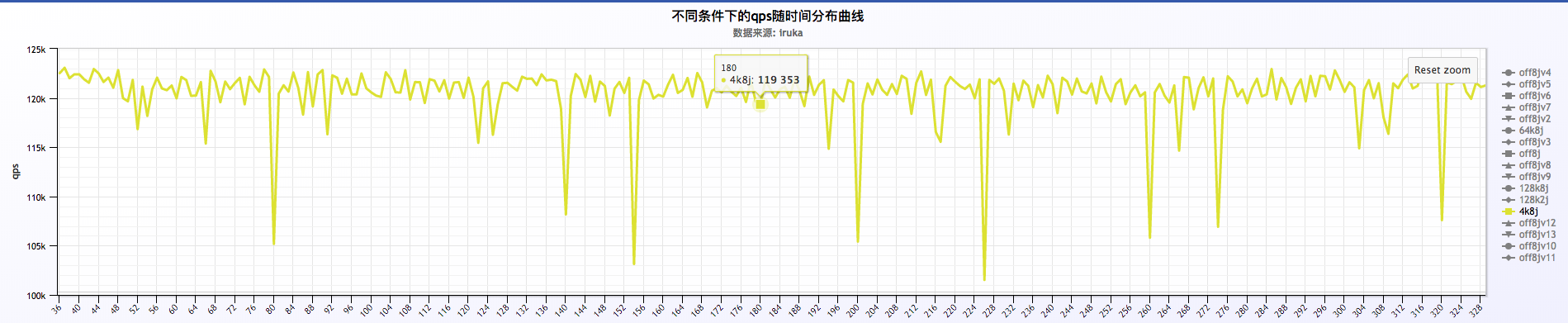
局部放大后: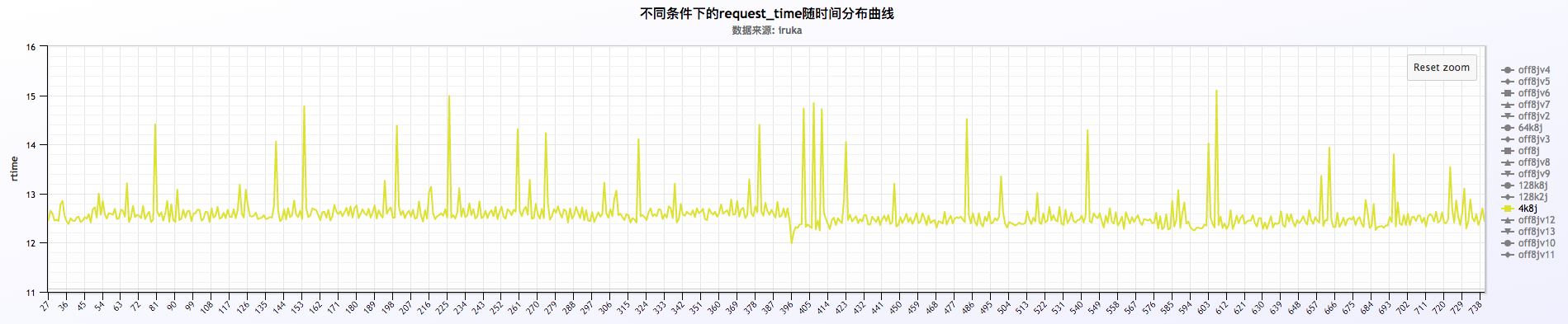
- 初步分析结果:
a . 从小米监控来看,压测过程几乎跑满了cpu,平均每个worker的cpu在92%左右,qps在 120.5k 左右,磁盘压力不算大
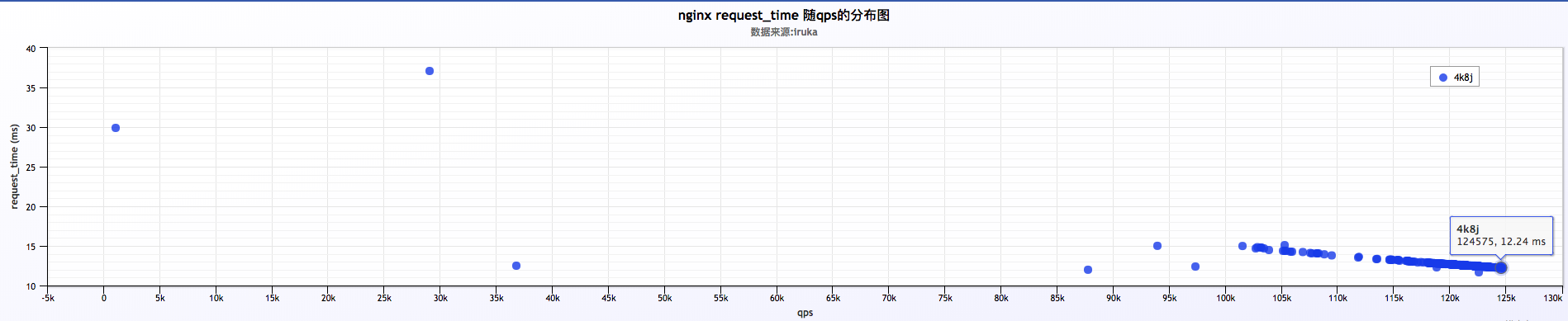
b . 分析大量日志来看,qps比较稳定,在 120k ~ 125k之间,request time在 12ms ~ 13ms之间,也比较稳定。两者之间的关系,qps随request time增加有所下降
2 . log buffer = 64k && 8 jump
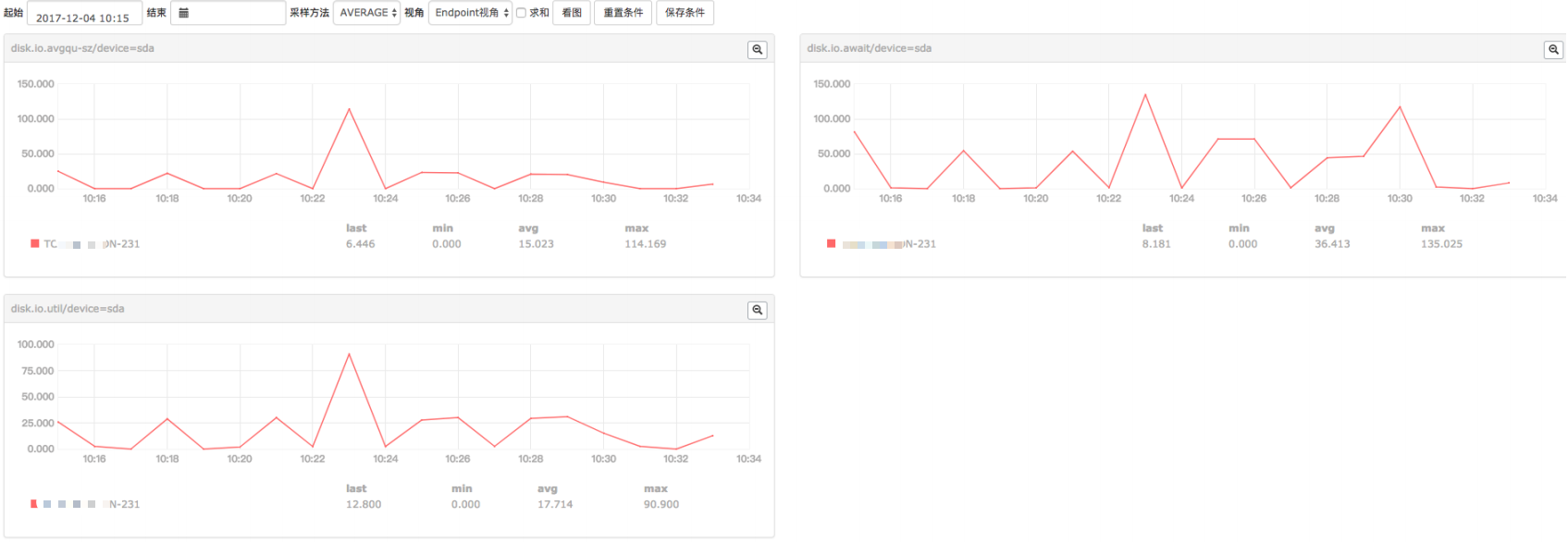
小米监控的结果(qps,cpu,request time,磁盘指标)
日志分析
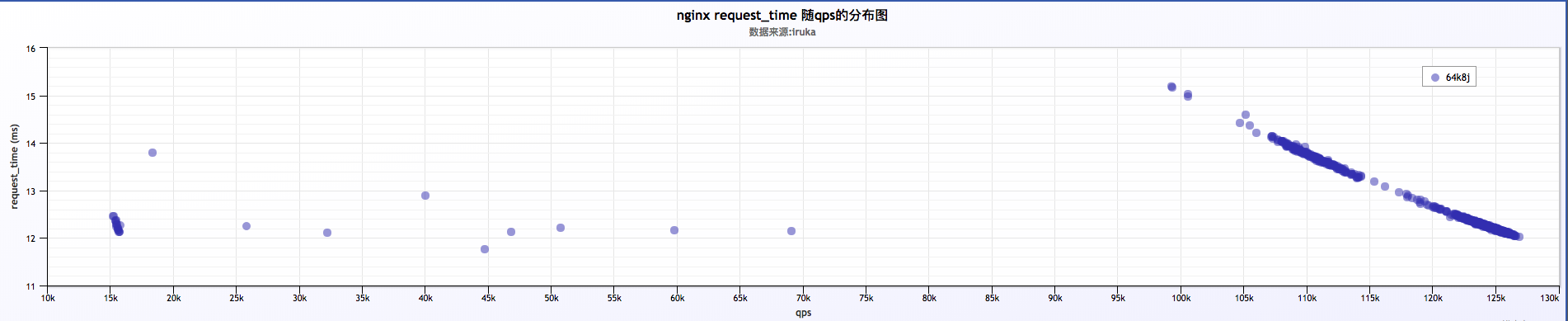
- 初步分析结果:
a . 从小米监控来看,压测过程ngxin的平均每个worker跑到88%左右的cpu,相较上面log buffer为 4k 的情况有所下降,qps平均为124k,有所上升;磁盘压力不大
b . 分析大量日志来看,qps比较稳定,在 120k ~ 125k之间,request time在 12ms ~ 13ms之间,也比较稳定。两者之间的关系,qps随request time增加有所下降
3 . log buffer = 128k && 8 jump
小米监控的结果(qps,cpu,request time,磁盘指标)
日志分析
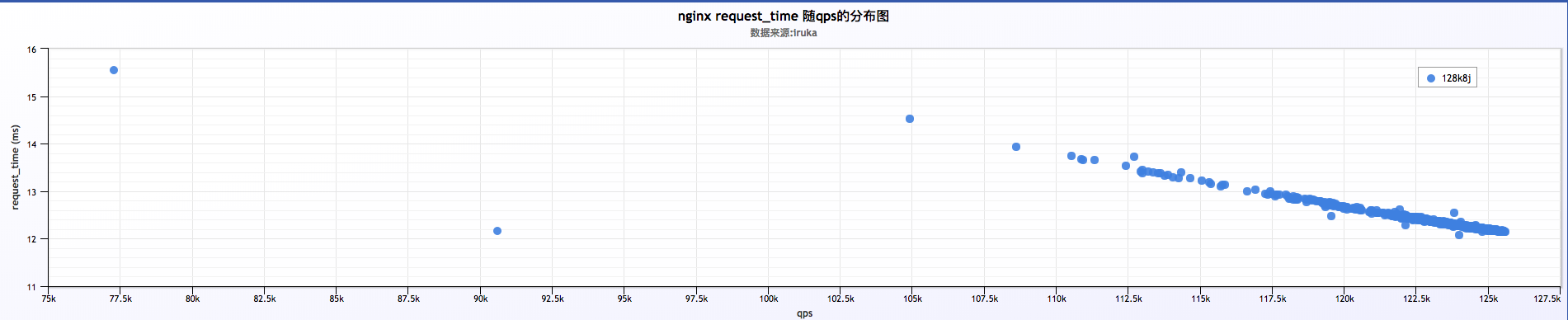
初步分析结果:
a . 从小米监控来看,nginx平均每个worker跑到 87% cpu,qps在 123.6k 左右。磁盘压力不大
b .分析大量日志来看,qps比较稳定,在 120k ~ 130k之间,request time在 12ms ~ 13ms之间,也比较稳定。两者之间的关系,qps随request time增加有所下降
4 . log buffer = 128k && 2 jump
日志分析
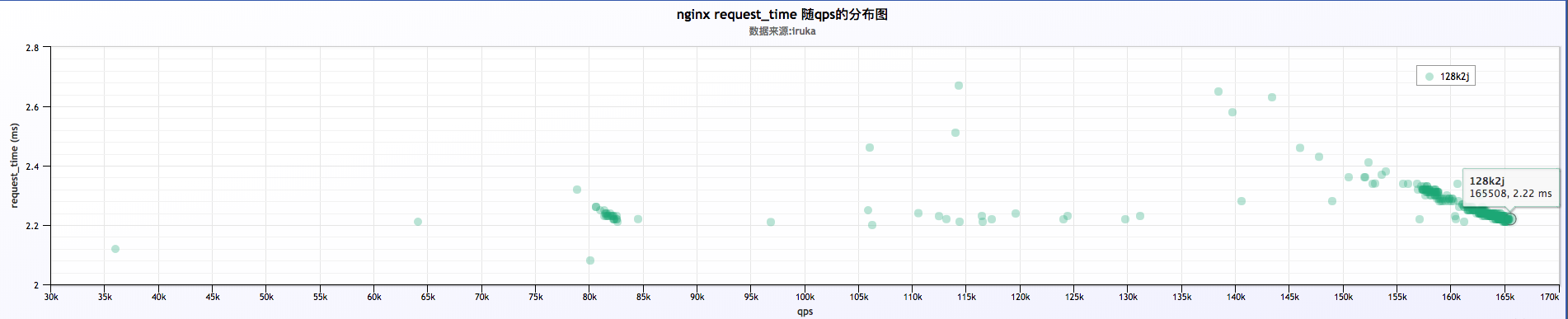

初步分析结果:
a . 分析大量日志来看,qps在 150k ~ 170k之间,并且qps相对不稳定。request time在 2ms ~ 3ms之间
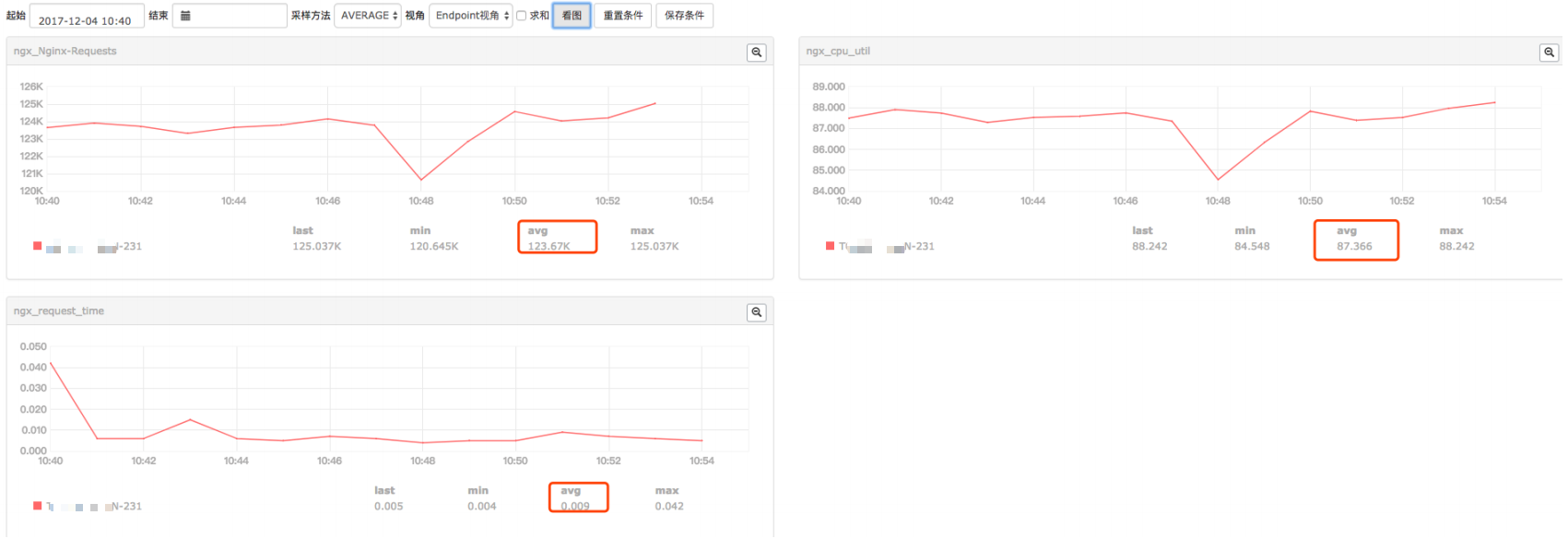
5 . log off && 8 jump
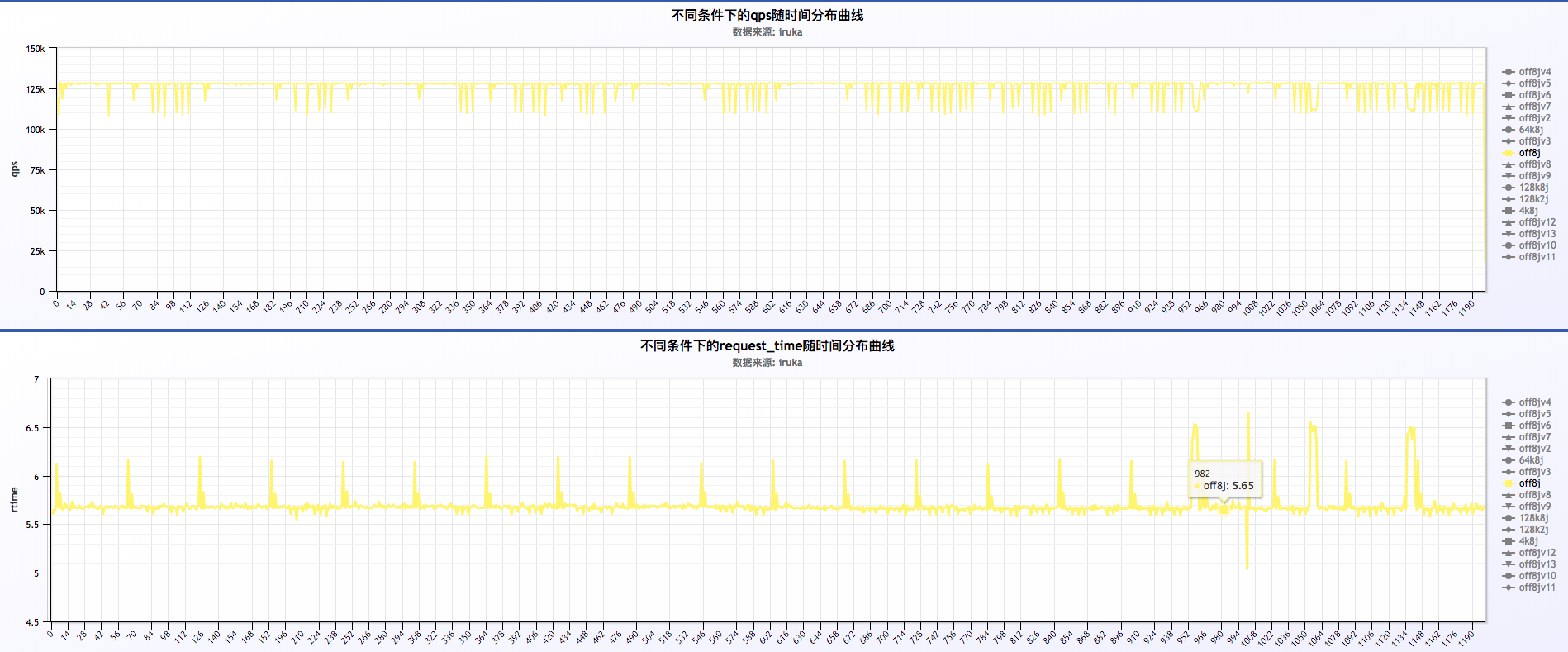
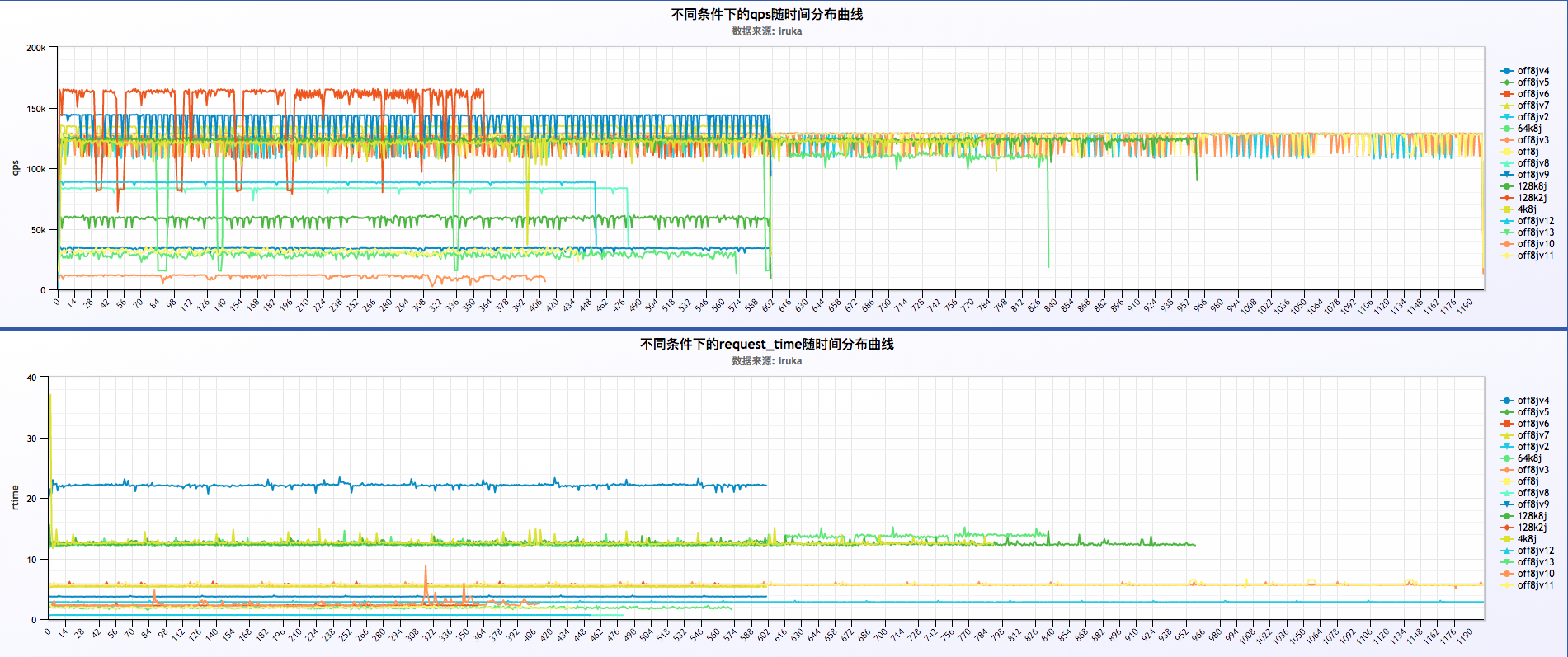
- 初步分析结果:
a . 压测nginx平均每个worker跑满88%左右的cpu,qps在128k左右,是同样条件下qps最高的,磁盘压力很小。
b. 图中可以看到关闭日志后request time相较其他几种情况很平稳,几乎是一条直线的状态
c. 所以可以考虑线上某些要求较为苛刻的客户针对性的关闭日志,提高服务的稳定性
d. request time有周期性(后面有说到)
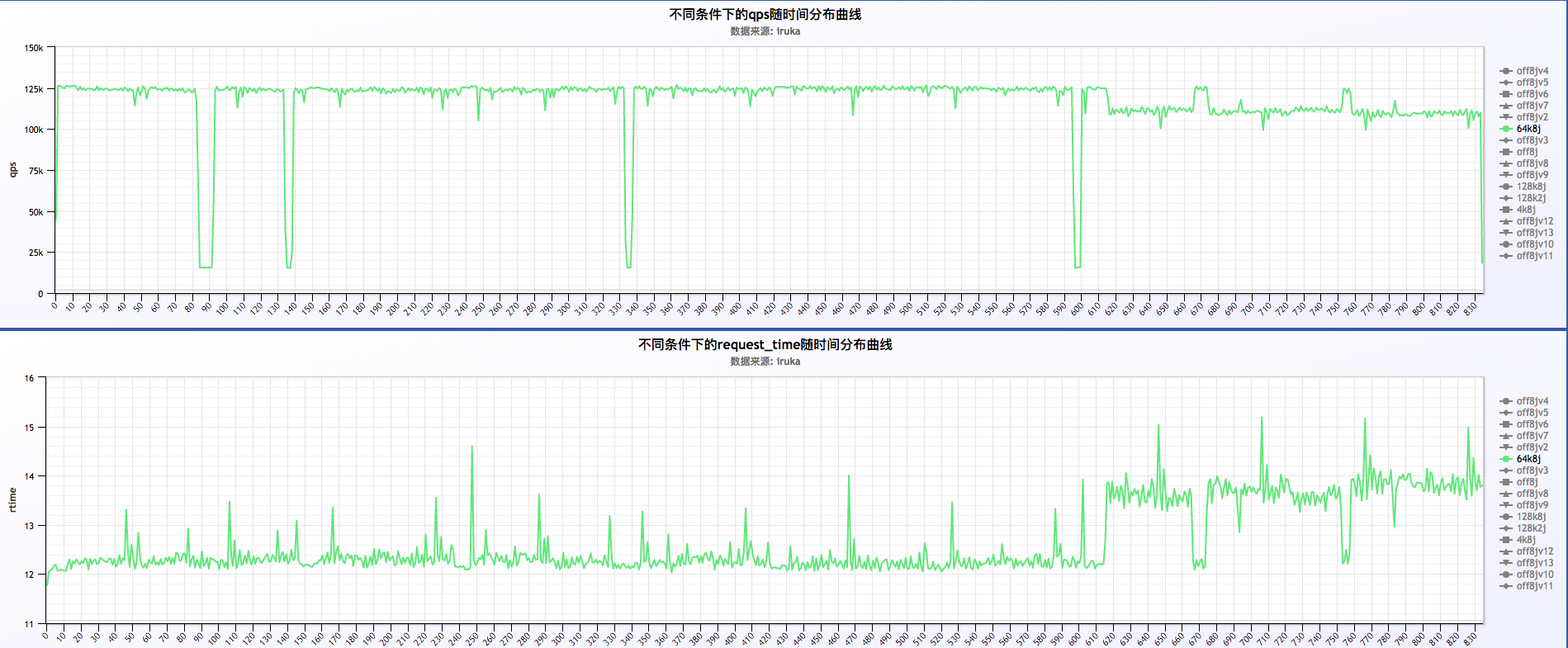
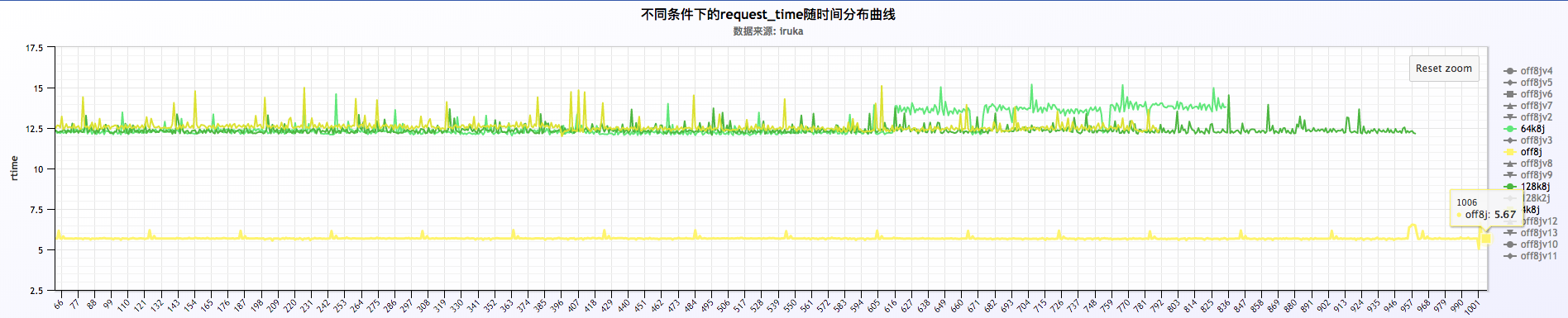
6 . 汇总来看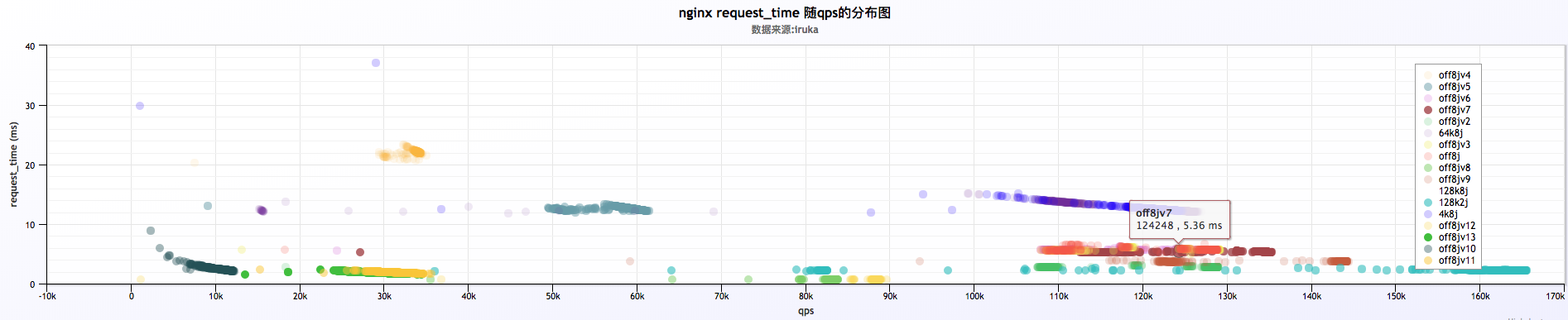
- 初步分析结果:
a . 从汇总的结果来看,抛开128k2j的那项,其他几个(4k8j,64k8j,128k8j)几乎都是重合状态,说明log buffer的大小对qps的影响不大,同时对request time的影响也不大
b . 128k2j的那项明显qps高出其他几项好多,同时request time低的也很明显
7 . 其他分析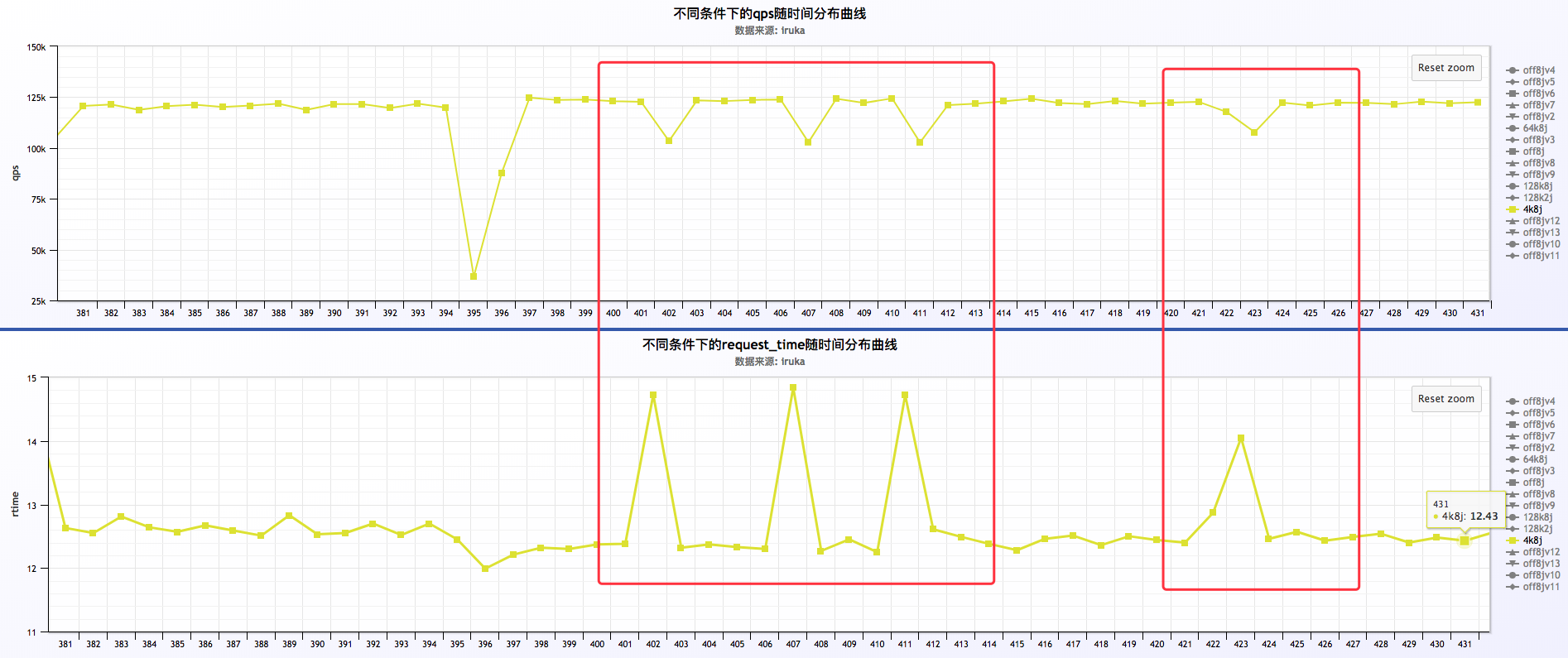
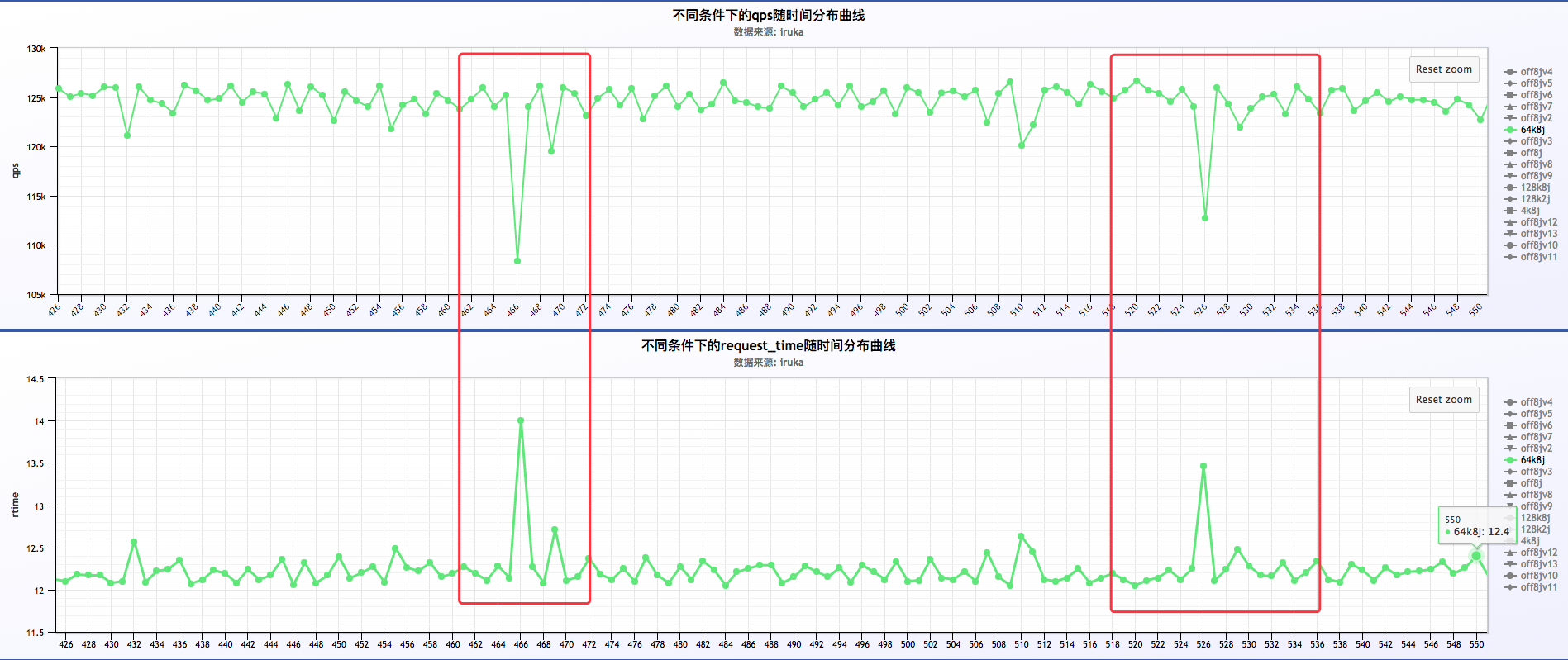
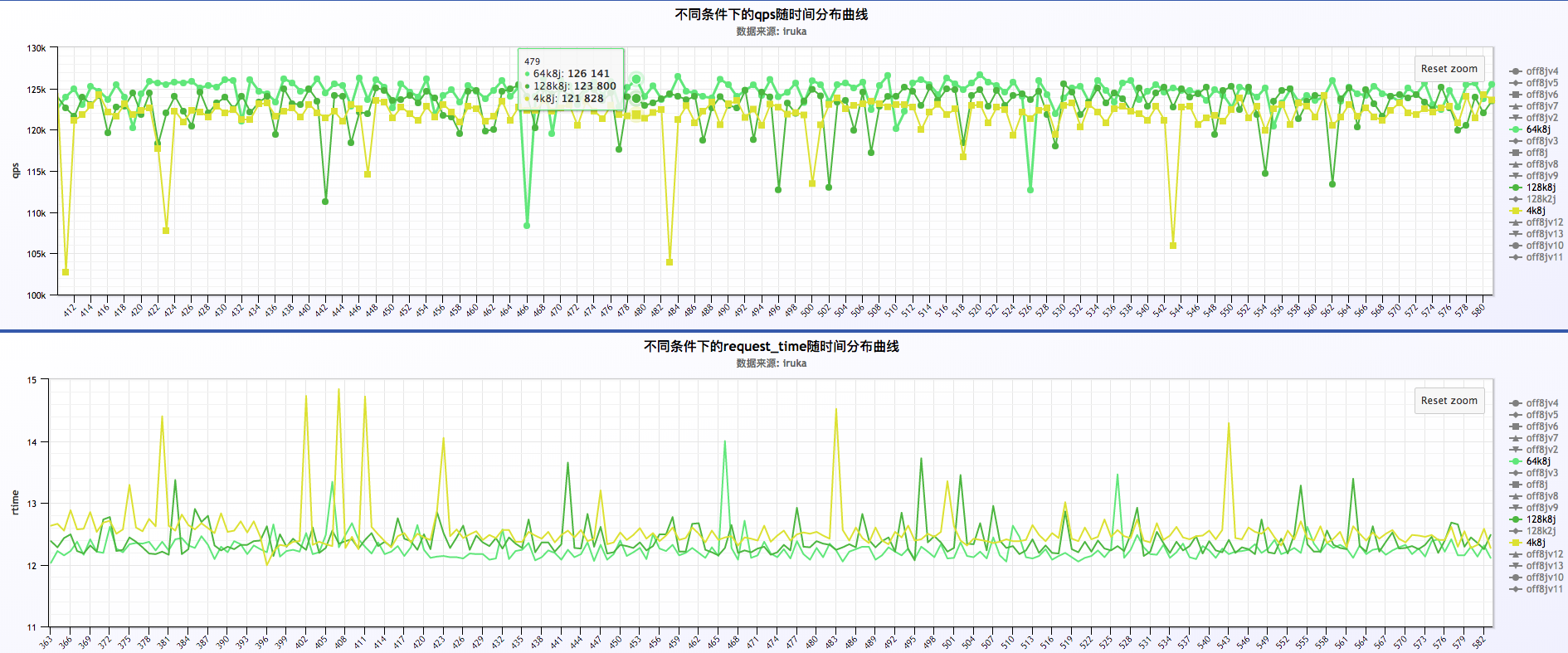
初步分析结果:
a . request time凸峰的时候,qps凹峰,即request time增加,qps减少
b . log buffer 分别为4k,64k,128k的情况下,log buffer 为64k的情况下表现最优(原因?将在《二》里详细分析)
探究过程的难点
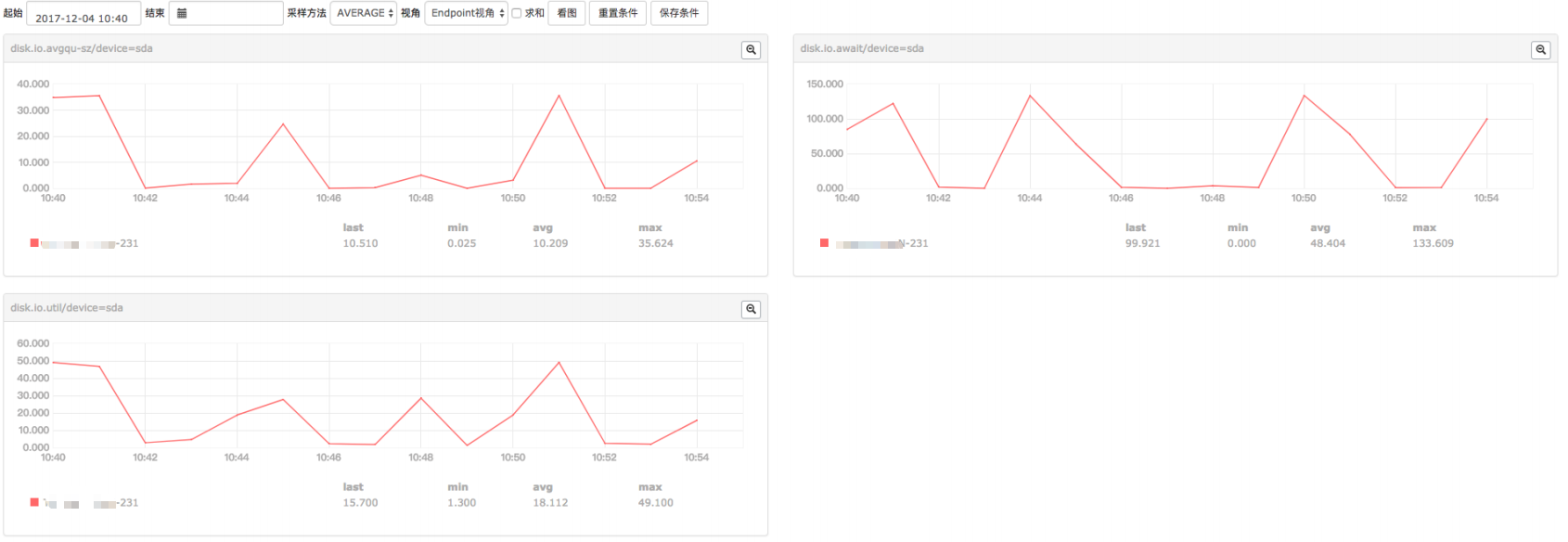
- 通过小米监控采集的指标精度很差,而且探究过程中由于小米监控自身的问题,导致很多曲线数据丢失,像类似cpu,磁盘压力等指标只能作为参考
- 日志的分析相对是比较精确的,但问题是数据量很大,由于qps在十万以上,压测10分钟,日志量可能就有接近10~15G,所以最后分析的样本总大小160G,这是一个比较大的数据量了。但从日志里只能分析得到qps,request time等指标
- 整个过程很难得出比较明确的结论,由于精度的问题,另外有其他变量的影响,分析得到的结论不会有很巨大的差距,得出很明确的结论。所以最终结论只能参考
- 当探究的精度更高的时候往往目标指标更容易受到其他变量的影响,要排除这些因素往往要做很多次测试,一次次排除分析,而且不一定找对影响变量,整体来讲,精细化的探究受其他因素影响较为敏感,探究更难
意外发现
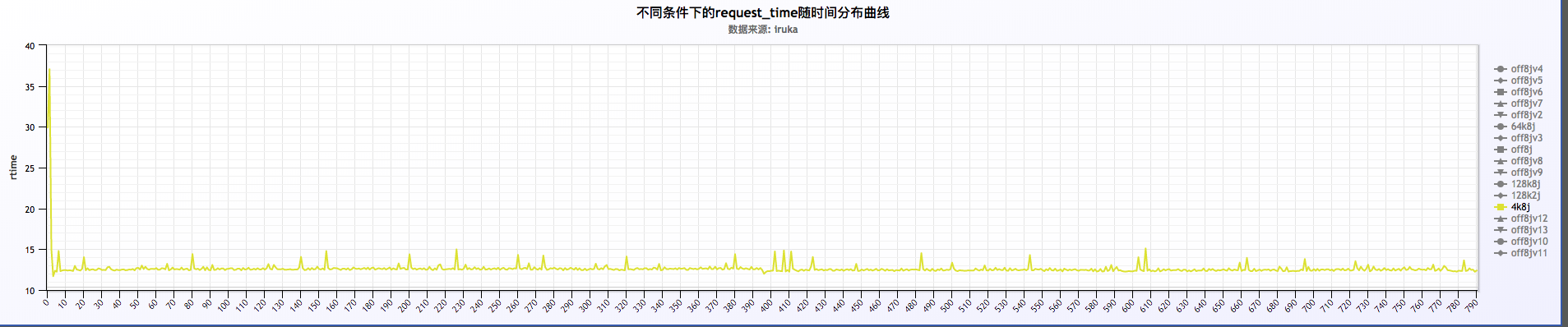
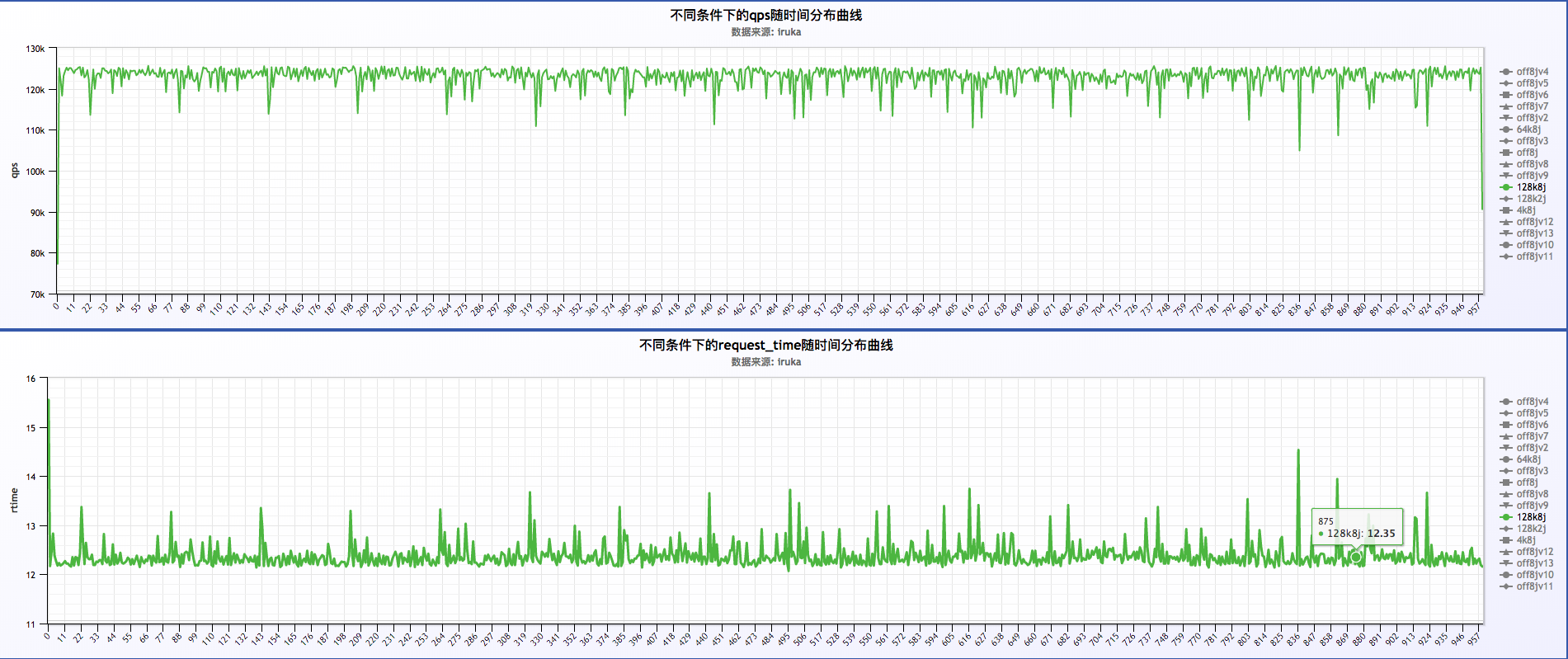
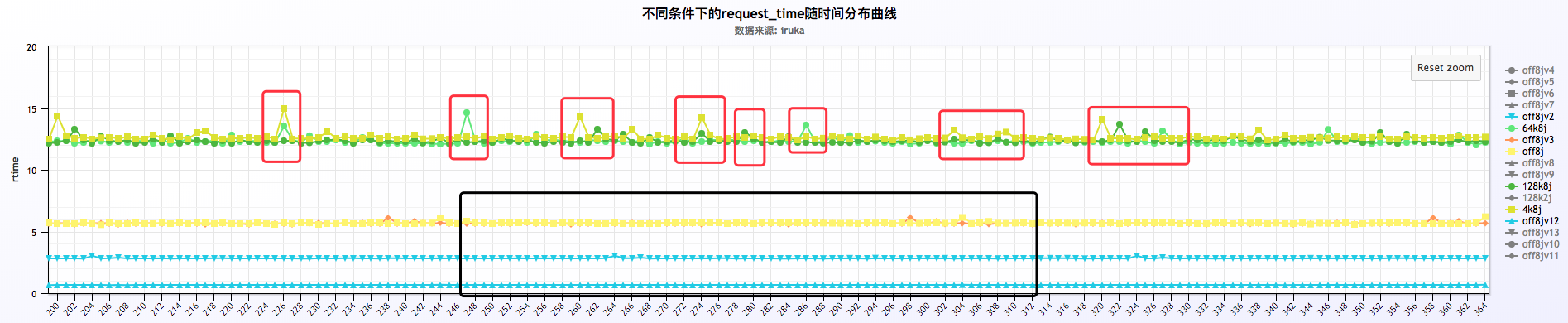
关闭或者不关闭日志的情况下,request time以每分钟的周期波动,如下: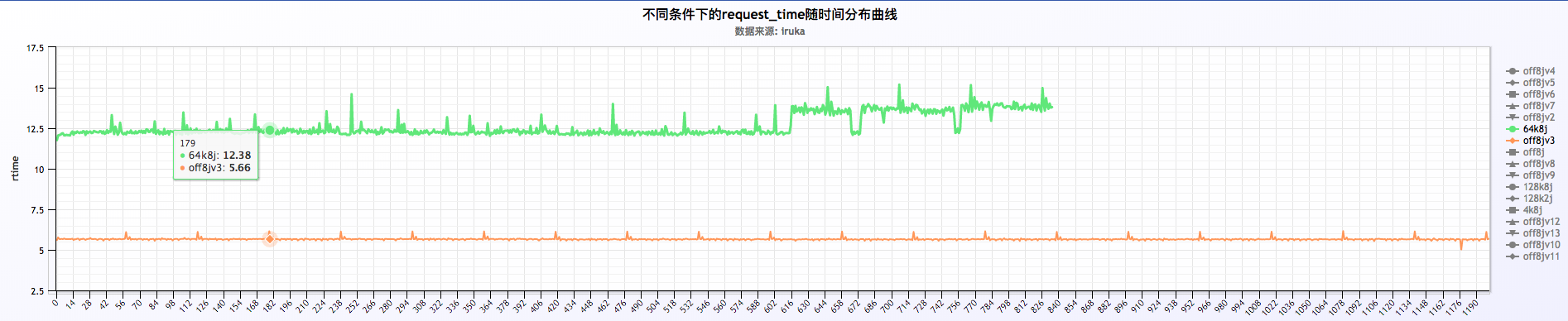
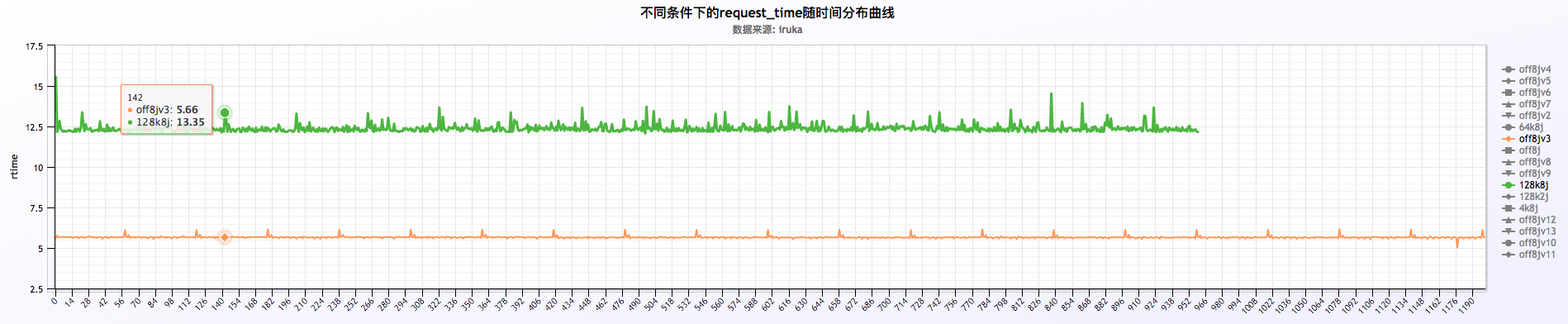
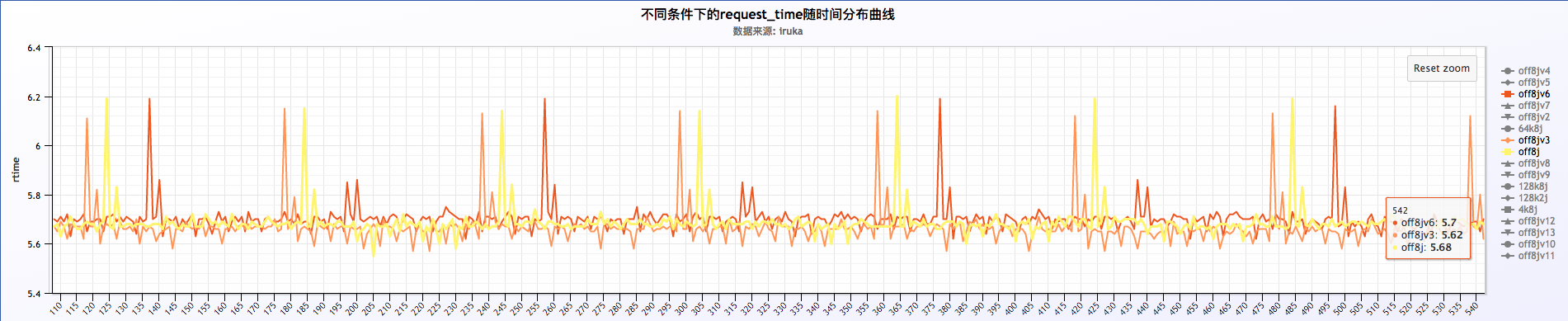
从上面三福图可以看出,request time成周期性波动,周期为60s。关于这块的深入探究另起篇幅进行研究。
