PROCESS STATE CODES D uninterruptible sleep (usually IO) R runnable (onrunqueue) S sleeping T traced or stopped Z a defunct ("zombie") process
For BSD formats and when the"stat" keyword is used, additional letters may be displayed: W has no resident pages < high-priority process N low-priority task L has pages locked into memory (for real-timeand custom IO)
2017-12-1410:36:25 root 3783150.00.000 ? D 10:270:00 \_ [kworker/5:18] 2017-12-1410:36:25 root 3783370.00.000 ? D 10:270:00 \_ [kworker/7:34] 2017-12-1410:36:25 root 3783390.00.000 ? D 10:270:00 \_ [kworker/7:36] 2017-12-1410:36:25 root 3783400.00.000 ? D 10:270:00 \_ [kworker/7:37] 2017-12-1410:36:25 root 3783430.00.000 ? D 10:270:00 \_ [kworker/7:40] 2017-12-1410:36:25 root 3783440.00.000 ? D 10:270:00 \_ [kworker/7:41] 2017-12-1410:36:25 root 3829180.00.000 ? D 10:310:00 \_ [kworker/3:1] 2017-12-1410:36:25 root 3838210.00.000 ? D 10:310:00 \_ [kworker/6:8] 2017-12-1410:36:25 root 3846270.00.000 ? D 10:320:00 \_ [kworker/3:2] 2017-12-1410:36:25 root 3846380.00.000 ? D 10:320:00 \_ [kworker/3:3] 2017-12-1410:36:25 root 3846400.00.000 ? D 10:320:00 \_ [kworker/0:0] 2017-12-1410:36:25 root 3846420.00.000 ? D 10:320:00 \_ [kworker/4:0] 2017-12-1410:36:25 root 3846430.00.000 ? D 10:320:00 \_ [kworker/4:1] 2017-12-1410:36:25 root 3846440.00.000 ? D 10:320:00 \_ [kworker/4:3] 2017-12-1410:36:25 root 3846450.00.000 ? D 10:320:00 \_ [kworker/4:4] 2017-12-1410:36:25 root 3846540.00.000 ? D 10:320:00 \_ [kworker/2:10] 2017-12-1410:36:25 root 3846550.00.000 ? D 10:320:00 \_ [kworker/2:11] 2017-12-1410:36:25 root 3846560.00.000 ? D 10:320:00 \_ [kworker/2:12] 2017-12-1410:36:25 root 3846590.00.000 ? D 10:320:00 \_ [kworker/5:1] 2017-12-1410:36:25 root 3846600.00.000 ? D 10:320:00 \_ [kworker/5:2] 2017-12-1410:36:25 root 3846610.00.000 ? D 10:320:00 \_ [kworker/5:3] 2017-12-1410:36:25 root 3846620.00.000 ? D 10:320:00 \_ [kworker/5:4] 2017-12-1410:36:25 root 3846630.00.000 ? D 10:320:00 \_ [kworker/5:5] 2017-12-1410:36:25 root 3932200.00.000 ? D 10:360:00 \_ [kworker/3:4] 2017-12-1410:36:25 root 3932220.00.000 ? D 10:360:00 \_ [kworker/3:5] 2017-12-1410:36:25 nobody 26464392.51.12626256191388 ? D Dec04 369:05 \_ nginx: worker process 2017-12-1410:36:25 nobody 26464402.91.12029968185368 ? D Dec04 422:39 \_ nginx: worker process 2017-12-1410:36:25 nobody 26464412.51.23371008208164 ? D Dec04 363:58 \_ nginx: worker process 2017-12-1410:36:25 nobody 26464423.41.12337132188544 ? D Dec04 490:30 \_ nginx: worker process 2017-12-1410:36:25 nobody 26464432.51.12646092195748 ? D Dec04 371:57 \_ nginx: worker process 2017-12-1410:36:25 nobody 26464454.61.12576596195664 ? D Dec04 662:33 \_ nginx: worker process
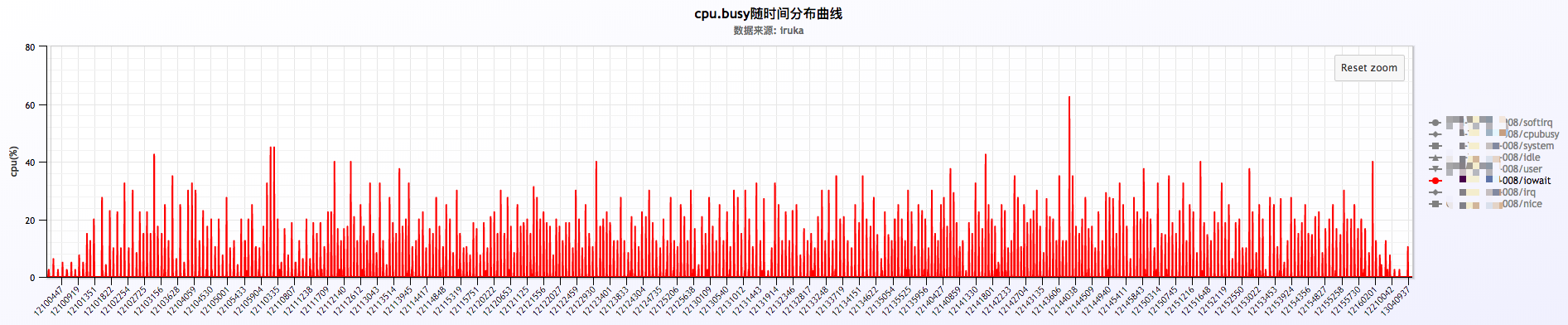
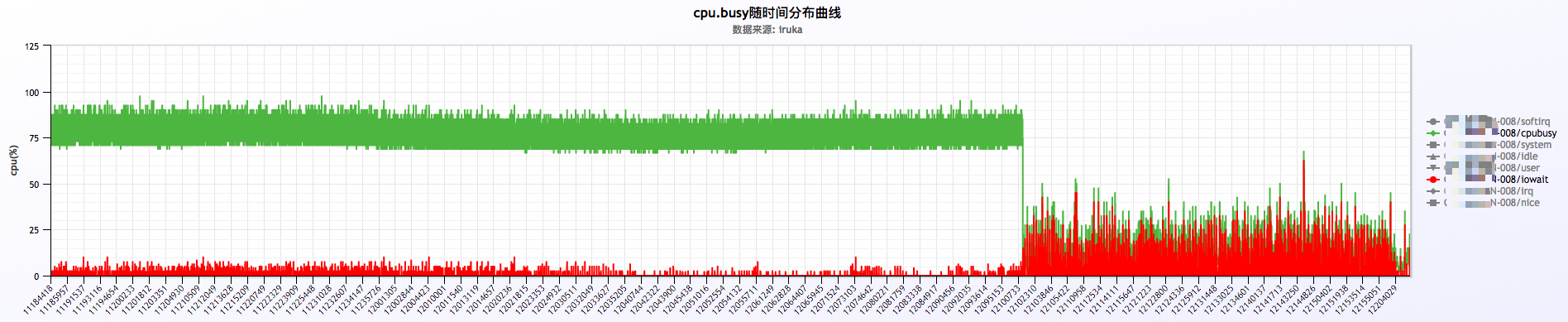
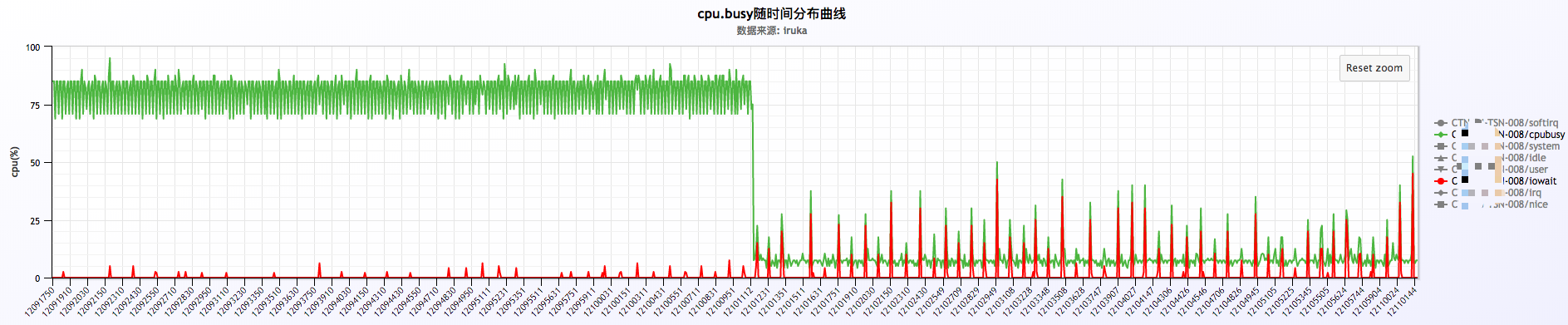
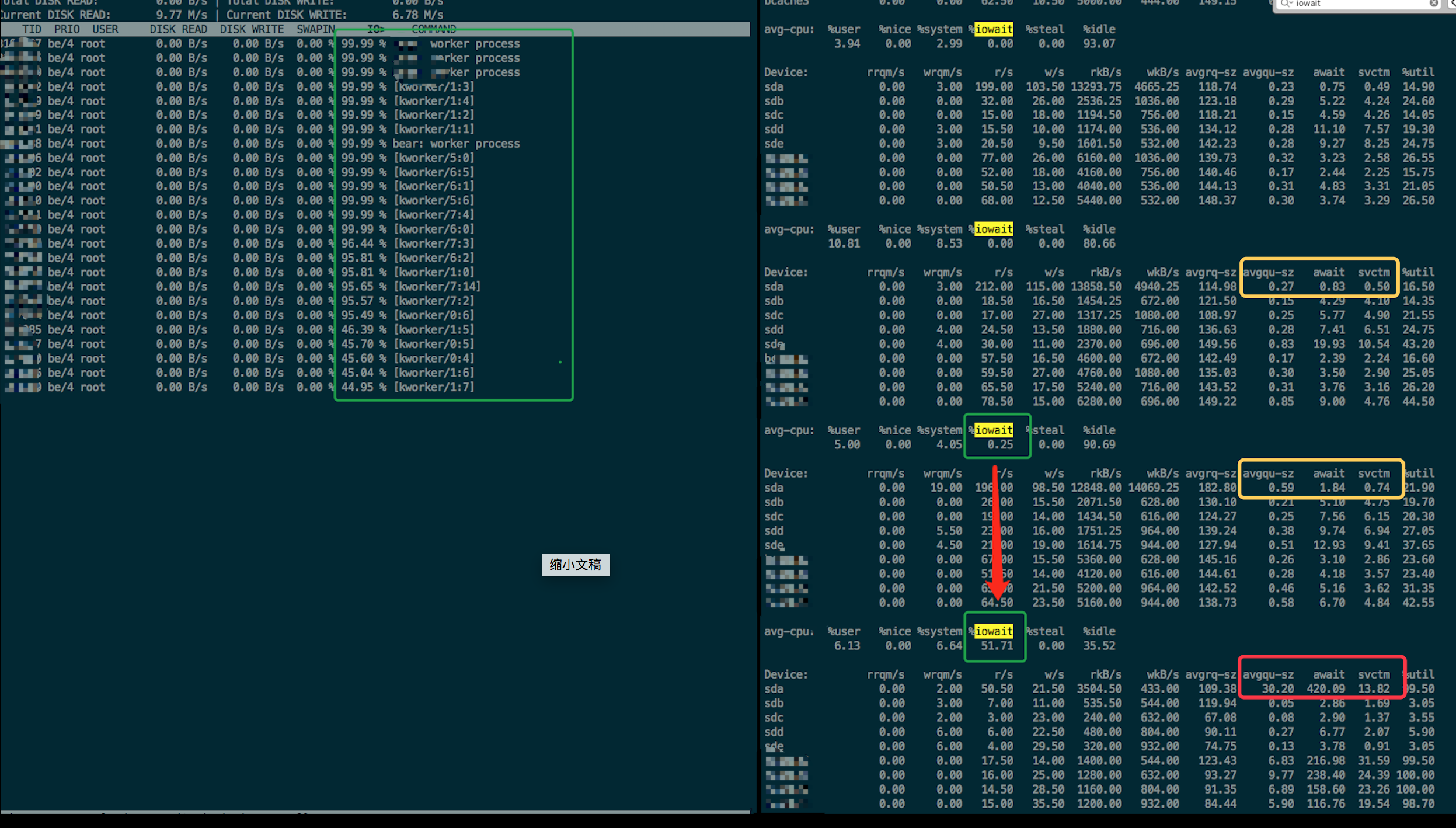
这里发现有nginx进程,这个并不奇怪,但是也有大量的kworker进程,一脸懵逼!
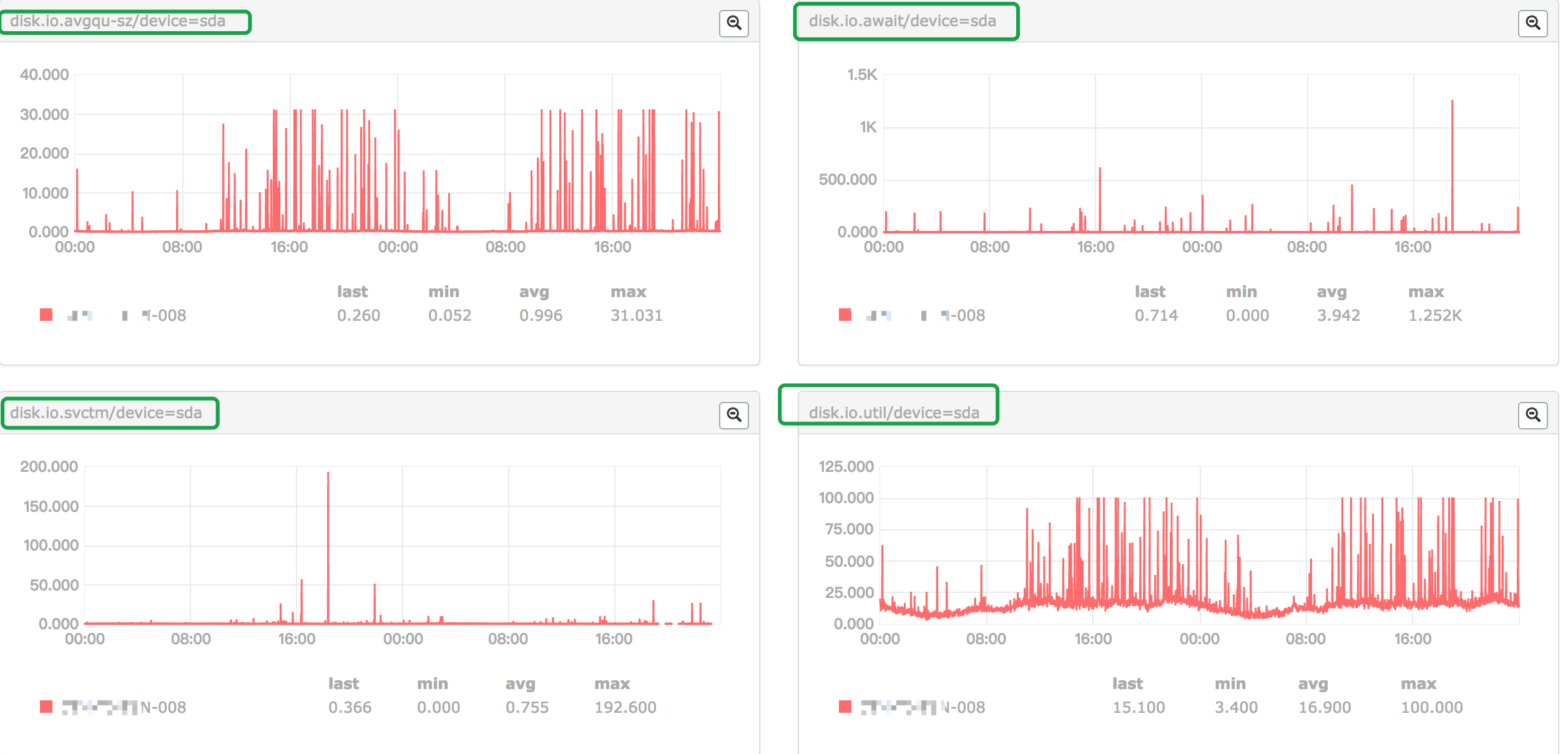
使用iotop
这台机器没有这个工具,本地下载了iotop的源码包后传上去,运行抛错:
1 2 3
Could notrun iotop as some of the requirements are not met: - Linux >= 2.6.20 with - I/O accounting support (CONFIG_TASKSTATS, CONFIG_TASK_DELAY_ACCT, CONFIG_TASK_IO_ACCOUNTING)
错误的原因很明显,内核版本不对,因为这台机器是裁剪了linux内核并重新进行了命名,那么怎么办?
也很简单,修改iotop/data.py,注释掉下面这段代码就行,骗一下iotop:
1 2 3 4 5 6 7 8 9 10 11 12
''' if not ioaccounting or not vm_event_counters: print('Could not run iotop as some of the requirements are not met:') print('- Linux >= 2.6.20 with') if not ioaccounting: print(' - I/O accounting support ' \ '(CONFIG_TASKSTATS, CONFIG_TASK_DELAY_ACCT, ' \ 'CONFIG_TASK_IO_ACCOUNTING)') if not vm_event_counters: print(' - VM event counters (CONFIG_VM_EVENT_COUNTERS)') sys.exit(1) '''
iotop命令的使用很简单,我常用命令:
1
python iotop.py -o
-o参数表示:only show processes or threads actually doing I/O。